 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing how Large Language Models perform against keyword-based searches for social science research data discovery
Jan 27, 2026This paper evaluates the performance of a large language model (LLM) based semantic search tool relative to a traditional keyword-based search for data discovery. Using real-world search behaviour, we compare outputs from a bespoke semantic search system applied to UKRI data services with the Consumer Data Research Centre (CDRC) keyword search. Analysis is based on 131 of the most frequently used search terms extracted from CDRC search logs between December 2023 and October 2024. We assess differences in the volume, overlap, ranking, and relevance of returned datasets using descriptive statistics, qualitative inspection, and quantitative similarity measures, including exact dataset overlap, Jaccard similarity, and cosine similarity derived from BERT embeddings. Results show that the semantic search consistently returns a larger number of results than the keyword search and performs particularly well for place based, misspelled, obscure, or complex queries. While the semantic search does not capture all keyword based results, the datasets returned are overwhelmingly semantically similar, with high cosine similarity scores despite lower exact overlap. Rankings of the most relevant results differ substantially between tools, reflecting contrasting prioritisation strategies. Case studies demonstrate that the LLM based tool is robust to spelling errors, interprets geographic and contextual relevance effectively, and supports natural-language queries that keyword search fails to resolve. Overall, the findings suggest that LLM driven semantic search offers a substantial improvement for data discovery, complementing rather than fully replacing traditional keyword-based approaches.
A deep learning approach to identify unhealthy advertisements in street view images
Jul 09, 2020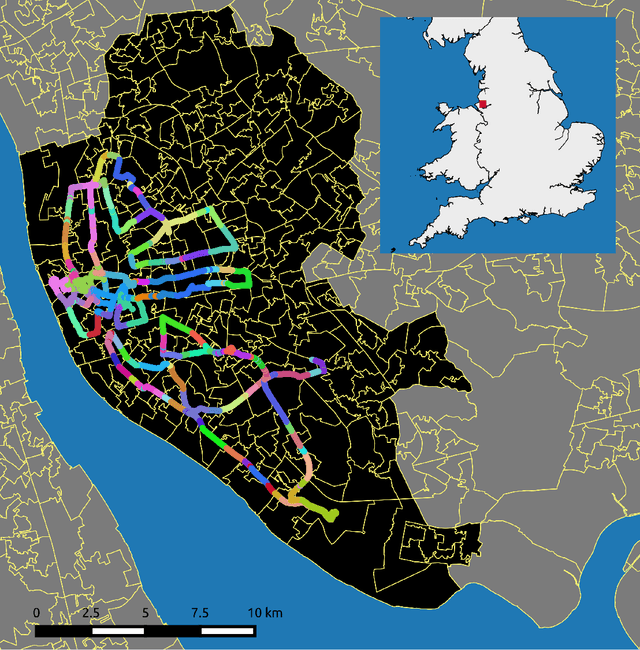
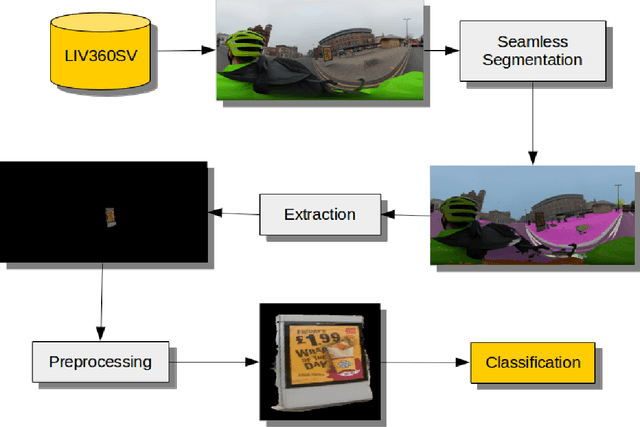
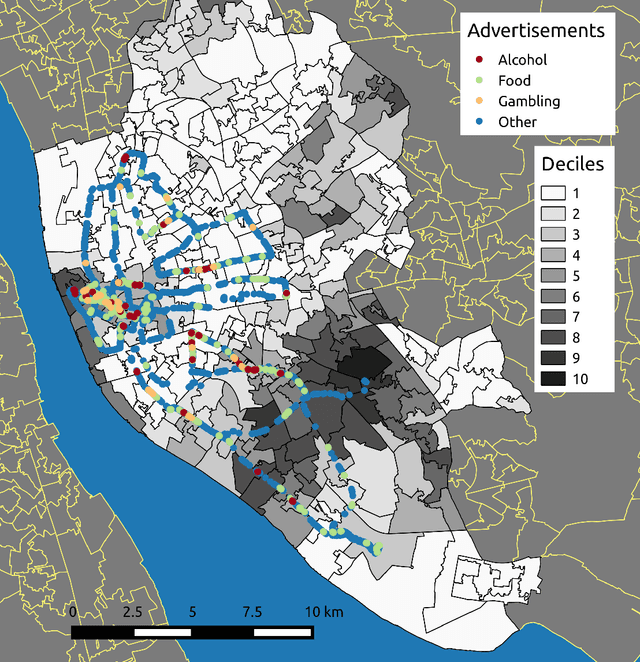
While outdoor advertisements are common features within towns and cities, they may reinforce social inequalities in health. Vulnerable populations in deprived areas may have greater exposure to fast food, gambling and alcohol advertisements encouraging their consumption. Understanding who is exposed and evaluating potential policy restrictions requires a substantial manual data collection effort. To address this problem we develop a deep learning workflow to automatically extract and classify unhealthy advertisements from street-level images. We introduce the Liverpool 360 degree Street View (LIV360SV) dataset for evaluating our workflow. The dataset contains 26,645, 360 degree, street-level images collected via cycling with a GoPro Fusion camera, recorded Jan 14th -- 18th 2020. 10,106 advertisements were identified and classified as food (1335), alcohol (217), gambling (149) and other (8405) (e.g., cars and broadband). We find evidence of social inequalities with a larger proportion of food advertisements located within deprived areas, and those frequented by students and children carrying excess weight. Our project presents a novel implementation for the incidental classification of street view images for identifying unhealthy advertisements, providing a means through which to identify areas that can benefit from tougher advertisement restriction policies for tackling social inequalities.