 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Architecture for Large-Scale Quantized Neural Networks on an FPGA-Based Dataflow Platform
Mar 13, 2018
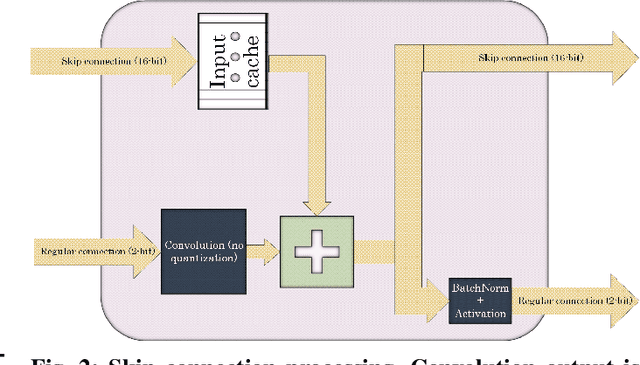
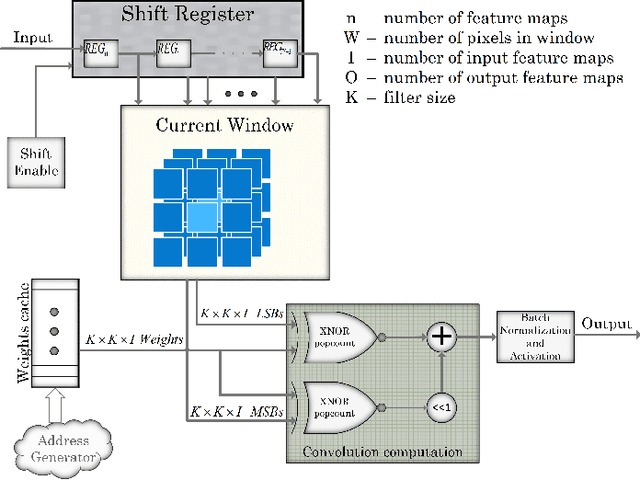
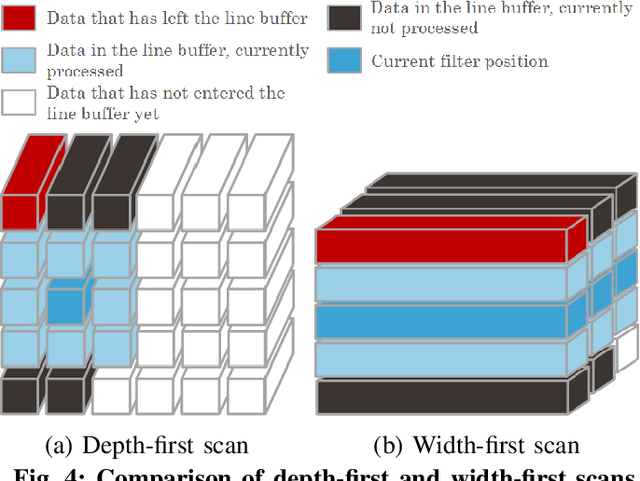
Deep neural networks (DNNs) are used by different applications that are executed on a range of computer architectures, from IoT devices to supercomputers. The footprint of these networks is huge as well as their computational and communication needs. In order to ease the pressure on resources, research indicates that in many cases a low precision representation (1-2 bit per parameter) of weights and other parameters can achieve similar accuracy while requiring less resources. Using quantized values enables the use of FPGAs to run NNs, since FPGAs are well fitted to these primitives; e.g., FPGAs provide efficient support for bitwise operations and can work with arbitrary-precision representation of numbers. This paper presents a new streaming architecture for running QNNs on FPGAs. The proposed architecture scales out better than alternatives, allowing us to take advantage of systems with multiple FPGAs. We also included support for skip connections, that are used in state-of-the art NNs, and shown that our architecture allows to add those connections almost for free. All this allowed us to implement an 18-layer ResNet for 224x224 images classification, achieving 57.5% top-1 accuracy. In addition, we implemented a full-sized quantized AlexNet. In contrast to previous works, we use 2-bit activations instead of 1-bit ones, which improves AlexNet's top-1 accuracy from 41.8% to 51.03% for the ImageNet classification. Both AlexNet and ResNet can handle 1000-class real-time classification on an FPGA. Our implementation of ResNet-18 consumes 5x less power and is 4x slower for ImageNet, when compared to the same NN on the latest Nvidia GPUs. Smaller NNs, that fit a single FPGA, are running faster then on GPUs on small (32x32) inputs, while consuming up to 20x less energy and power.