 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Large Scale Synthetic Graph Dataset Generation
Oct 06, 2022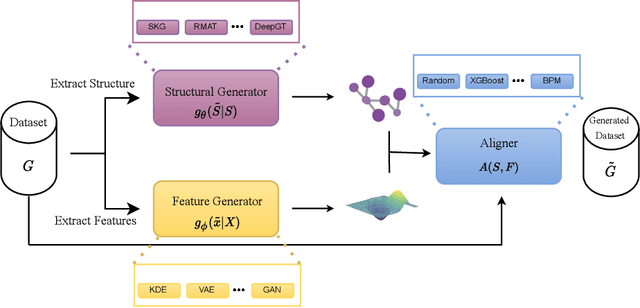
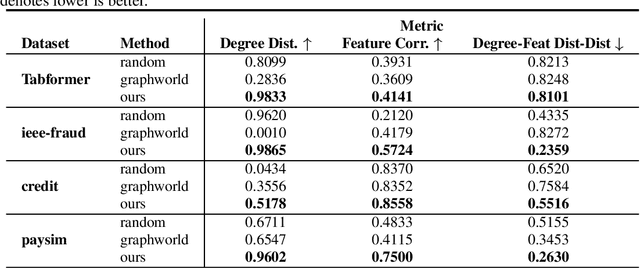
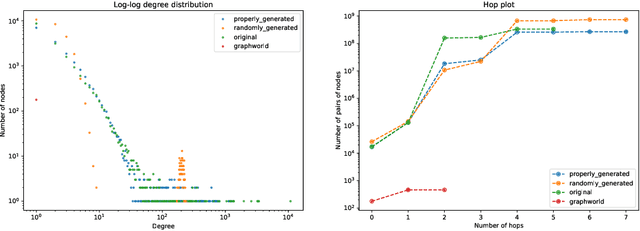
Recently there has been increasing interest in developing and deploying deep graph learning algorithms for many graph analysis tasks such as node and edge classification, link prediction, and clustering with numerous practical applications such as fraud detection, drug discovery, or recommender systems. Allbeit there is a limited number of publicly available graph-structured datasets, most of which are tiny compared to production-sized applications with trillions of edges and billions of nodes. Further, new algorithms and models are benchmarked across similar datasets with similar properties. In this work, we tackle this shortcoming by proposing a scalable synthetic graph generation tool that can mimic the original data distribution of real-world graphs and scale them to arbitrary sizes. This tool can be used then to learn a set of parametric models from proprietary datasets that can subsequently be released to researchers to study various graph methods on the synthetic data increasing prototype development and novel applications. Finally, the performance of the graph learning algorithms depends not only on the size but also on the dataset's structure. We show how our framework generalizes across a set of datasets, mimicking both structural and feature distributions as well as its scalability across varying dataset sizes.