 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQUWA: Signal Quality Aware DNN Architecture for Enhanced Accuracy in Atrial Fibrillation Detection from Noisy PPG Signals
Apr 15, 2024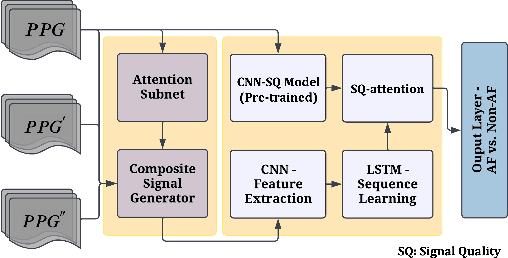
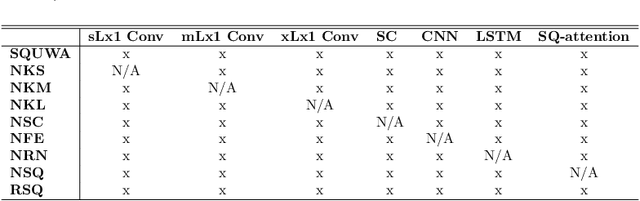
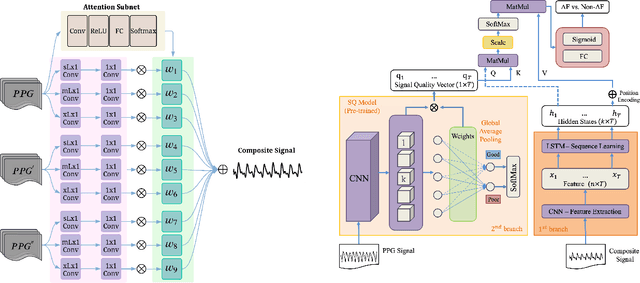
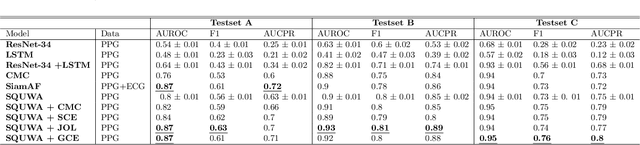
Atrial fibrillation (AF), a common cardiac arrhythmia, significantly increases the risk of stroke, heart disease, and mortality. Photoplethysmography (PPG) offers a promising solution for continuous AF monitoring, due to its cost efficiency and integration into wearable devices. Nonetheless, PPG signals are susceptible to corruption from motion artifacts and other factors often encountered in ambulatory settings. Conventional approaches typically discard corrupted segments or attempt to reconstruct original signals, allowing for the use of standard machine learning techniques. However, this reduces dataset size and introduces biases, compromising prediction accuracy and the effectiveness of continuous monitoring. We propose a novel deep learning model, Signal Quality Weighted Fusion of Attentional Convolution and Recurrent Neural Network (SQUWA), designed to learn how to retain accurate predictions from partially corrupted PPG. Specifically, SQUWA innovatively integrates an attention mechanism that directly considers signal quality during the learning process, dynamically adjusting the weights of time series segments based on their quality. This approach enhances the influence of higher-quality segments while reducing that of lower-quality ones, effectively utilizing partially corrupted segments. This approach represents a departure from the conventional methods that exclude such segments, enabling the utilization of a broader range of data, which has great implications for less disruption when monitoring of AF risks and more accurate estimation of AF burdens. Our extensive experiments show that SQUWA outperform existing PPG-based models, achieving the highest AUCPR of 0.89 with label noise mitigation. This also exceeds the 0.86 AUCPR of models trained with using both electrocardiogram (ECG) and PPG data.
Deep Attention Recurrent Q-Network
Dec 05, 2015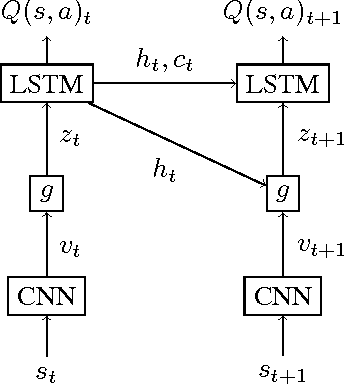
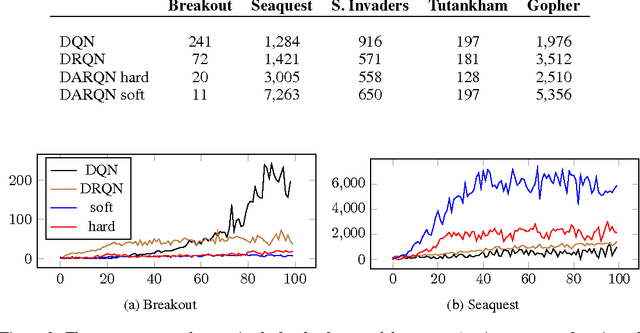
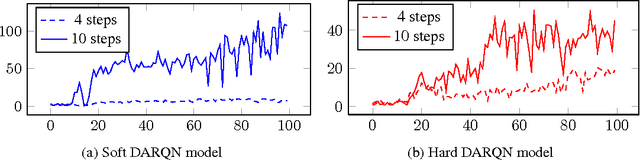

A deep learning approach to reinforcement learning led to a general learner able to train on visual input to play a variety of arcade games at the human and superhuman levels. Its creators at the Google DeepMind's team called the approach: Deep Q-Network (DQN). We present an extension of DQN by "soft" and "hard" attention mechanisms. Tests of the proposed Deep Attention Recurrent Q-Network (DARQN) algorithm on multiple Atari 2600 games show level of performance superior to that of DQN. Moreover, built-in attention mechanisms allow a direct online monitoring of the training process by highlighting the regions of the game screen the agent is focusing on when making decisions.