 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Action Recognition
Dec 14, 2020
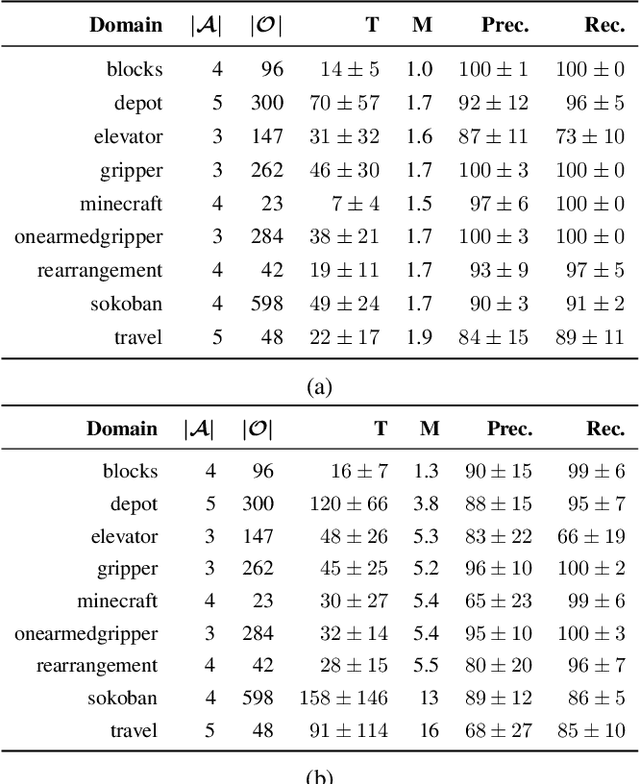
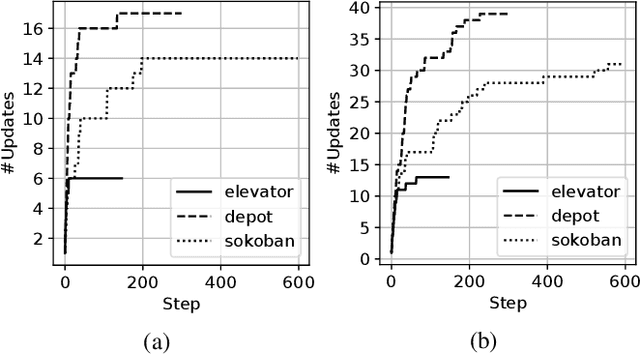
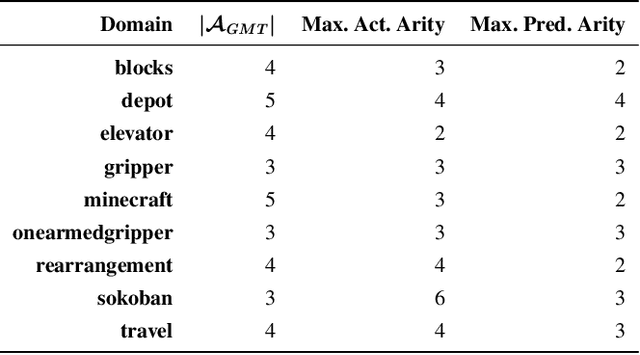
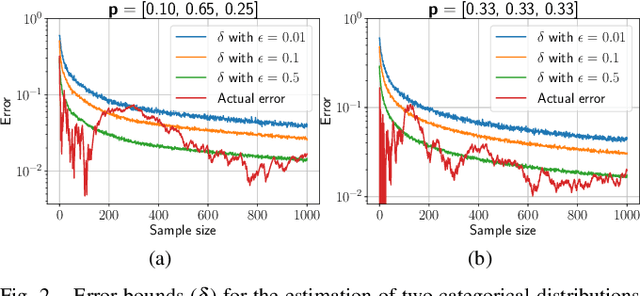
Recognition in planning seeks to find agent intentions, goals or activities given a set of observations and a knowledge library (e.g. goal states, plans or domain theories). In this work we introduce the problem of Online Action Recognition. It consists in recognizing, in an open world, the planning action that best explains a partially observable state transition from a knowledge library of first-order STRIPS actions, which is initially empty. We frame this as an optimization problem, and propose two algorithms to address it: Action Unification (AU) and Online Action Recognition through Unification (OARU). The former builds on logic unification and generalizes two input actions using weighted partial MaxSAT. The latter looks for an action within the library that explains an observed transition. If there is such action, it generalizes it making use of AU, building in this way an AU hierarchy. Otherwise, OARU inserts a Trivial Grounded Action (TGA) in the library that explains just that transition. We report results on benchmarks from the International Planning Competition and PDDLGym, where OARU recognizes actions accurately with respect to expert knowledge, and shows real-time performance.
Leveraging Multiple Environments for Learning and Decision Making: a Dismantling Use Case
Sep 18, 2020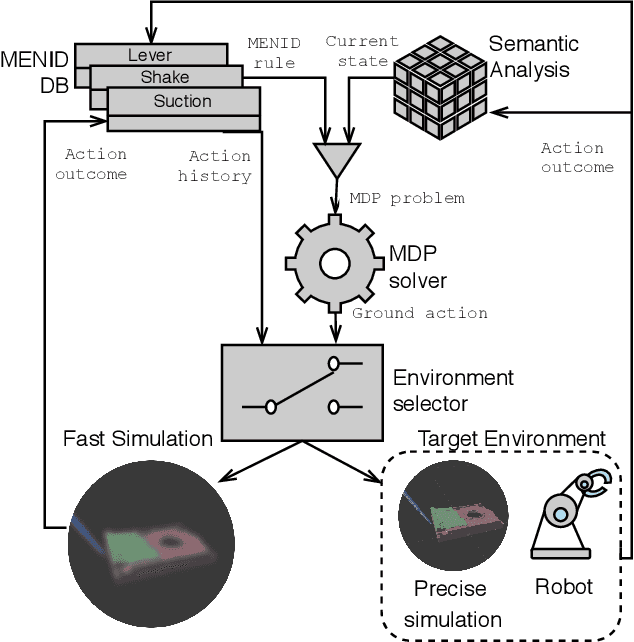
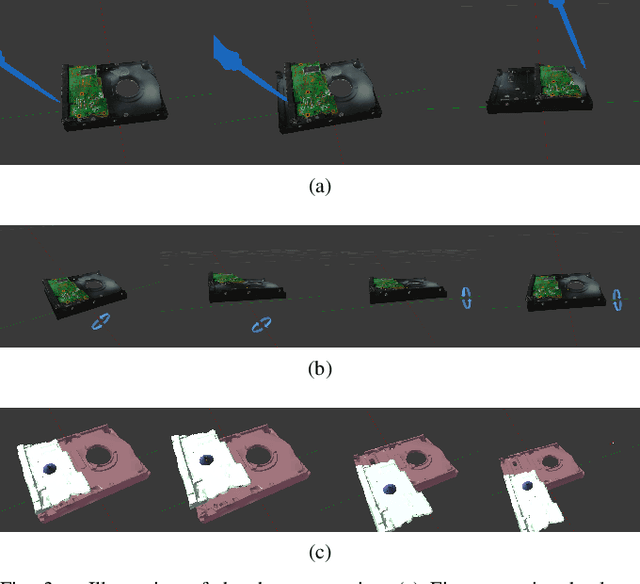
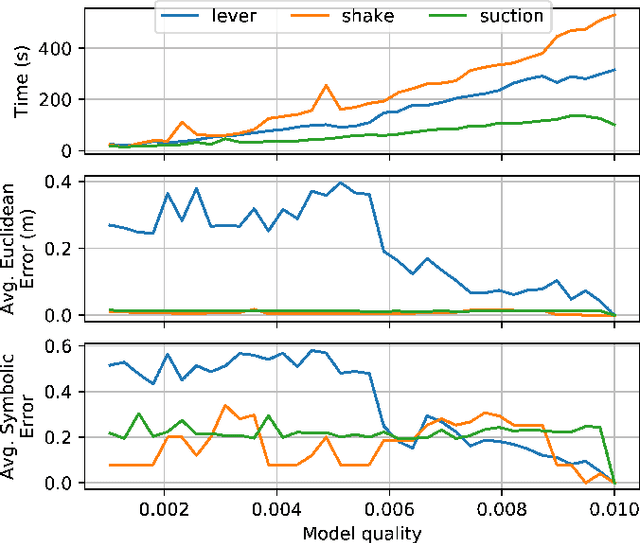
Learning is usually performed by observing real robot executions. Physics-based simulators are a good alternative for providing highly valuable information while avoiding costly and potentially destructive robot executions. We present a novel approach for learning the probabilities of symbolic robot action outcomes. This is done leveraging different environments, such as physics-based simulators, in execution time. To this end, we propose MENID (Multiple Environment Noise Indeterministic Deictic) rules, a novel representation able to cope with the inherent uncertainties present in robotic tasks. MENID rules explicitly represent each possible outcomes of an action, keep memory of the source of the experience, and maintain the probability of success of each outcome. We also introduce an algorithm to distribute actions among environments, based on previous experiences and expected gain. Before using physics-based simulations, we propose a methodology for evaluating different simulation settings and determining the least time-consuming model that could be used while still producing coherent results. We demonstrate the validity of the approach in a dismantling use case, using a simulation with reduced quality as simulated system, and a simulation with full resolution where we add noise to the trajectories and some physical parameters as a representation of the real system.
STRIPS Action Discovery
Feb 04, 2020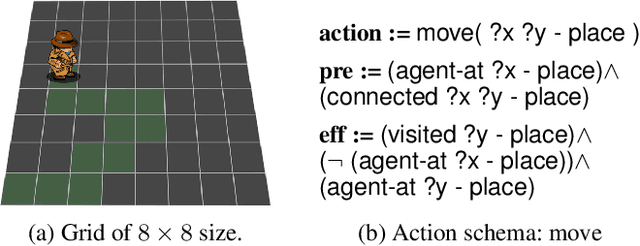


The problem of specifying high-level knowledge bases for planning becomes a hard task in realistic environments. This knowledge is usually handcrafted and is hard to keep updated, even for system experts. Recent approaches have shown the success of classical planning at synthesizing action models even when all intermediate states are missing. These approaches can synthesize action schemas in Planning Domain Definition Language (PDDL) from a set of execution traces each consisting, at least, of an initial and final state. In this paper, we propose a new algorithm to unsupervisedly synthesize STRIPS action models with a classical planner when action signatures are unknown. In addition, we contribute with a compilation to classical planning that mitigates the problem of learning static predicates in the action model preconditions, exploits the capabilities of SAT planners with parallel encodings to compute action schemas and validate all instances. Our system is flexible in that it supports the inclusion of partial input information that may speed up the search. We show through several experiments how learned action models generalize over unseen planning instances.