 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Reasoning with Differentiable Graph Transformations
Jul 20, 2021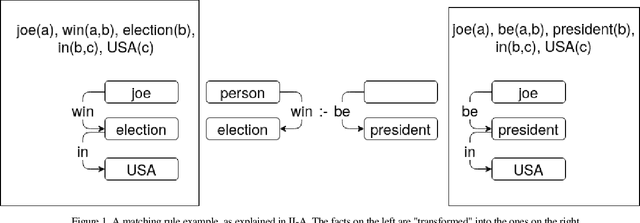
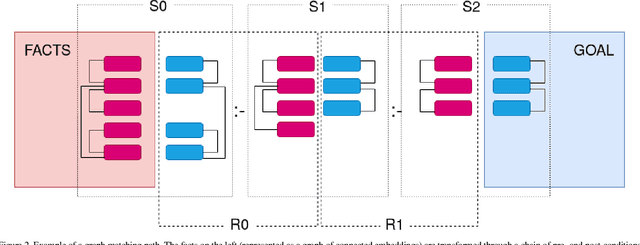
This paper introduces a differentiable semantic reasoner, where rules are presented as a relevant set of graph transformations. These rules can be written manually or inferred by a set of facts and goals presented as a training set. While the internal representation uses embeddings in a latent space, each rule can be expressed as a set of predicates conforming to a subset of Description Logic.
Dispatcher: A Message-Passing Approach To Language Modelling
May 09, 2021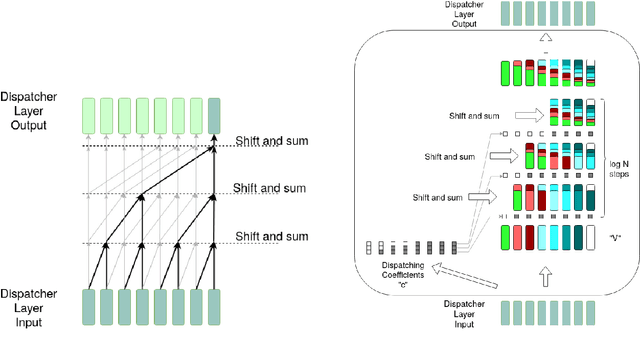
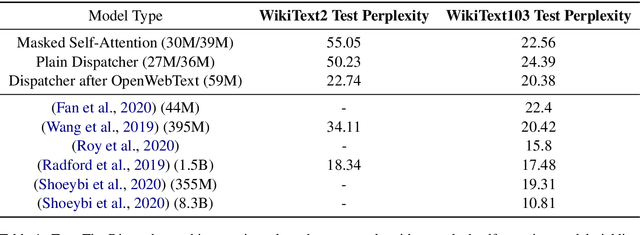
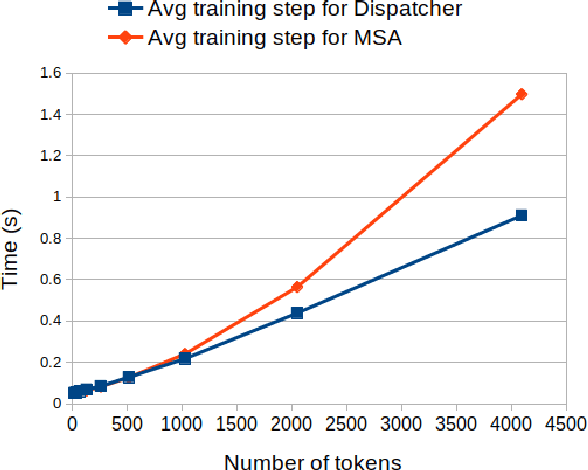
This paper proposes a message-passing mechanism to address language modelling. A new layer type is introduced that aims to substitute self-attention. The system is shown to be competitive with existing methods: Given N tokens, the computational complexity is O(N log N) and the memory complexity is O(N) under reasonable assumptions. In the end, the Dispatcher layer is seen to achieve comparable perplexity to prior results while being more efficient
Pynsett: A programmable relation extractor
Jul 04, 2020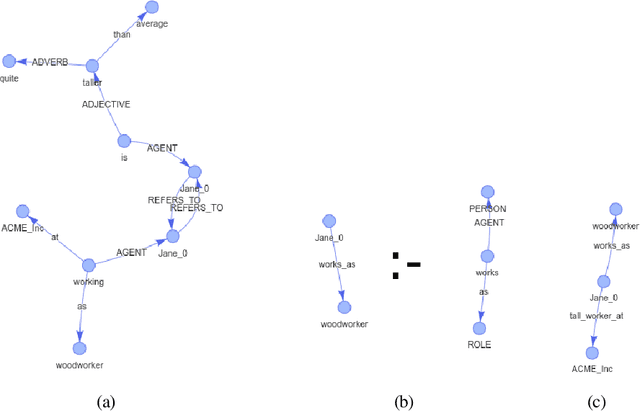
This paper proposes a programmable relation extraction method for the English language by parsing texts into semantic graphs. A person can define rules in plain English that act as matching patterns onto the graph representation. These rules are designed to capture the semantic content of the documents, allowing for flexibility and ad-hoc entities. Relation extraction is a complex task that typically requires sizeable training corpora. The method proposed here is ideal for extracting specialized ontologies in a limited collection of documents.
Named Entity Disambiguation using Deep Learning on Graphs
Oct 22, 2018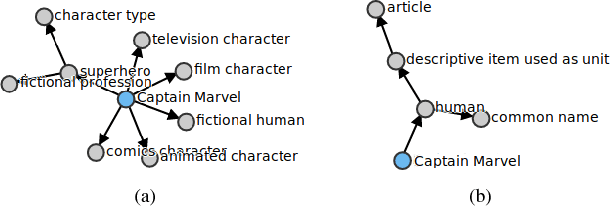

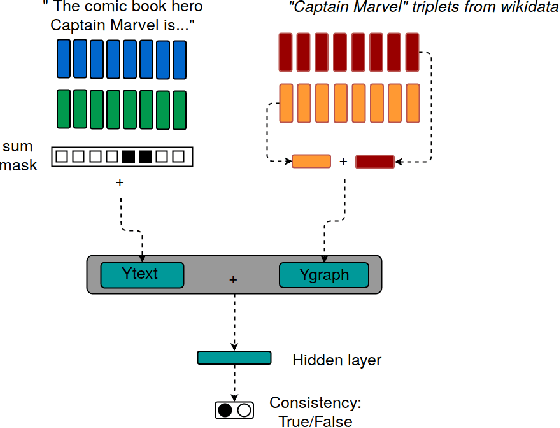

We tackle \ac{NED} by comparing entities in short sentences with \wikidata{} graphs. Creating a context vector from graphs through deep learning is a challenging problem that has never been applied to \ac{NED}. Our main contribution is to present an experimental study of recent neural techniques, as well as a discussion about which graph features are most important for the disambiguation task. In addition, a new dataset (\wikidatadisamb{}) is created to allow a clean and scalable evaluation of \ac{NED} with \wikidata{} entries, and to be used as a reference in future research. In the end our results show that a \ac{Bi-LSTM} encoding of the graph triplets performs best, improving upon the baseline models and scoring an \rm{F1} value of $91.6\%$ on the \wikidatadisamb{} test set