Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDispatcher: A Message-Passing Approach To Language Modelling
Paper and Code
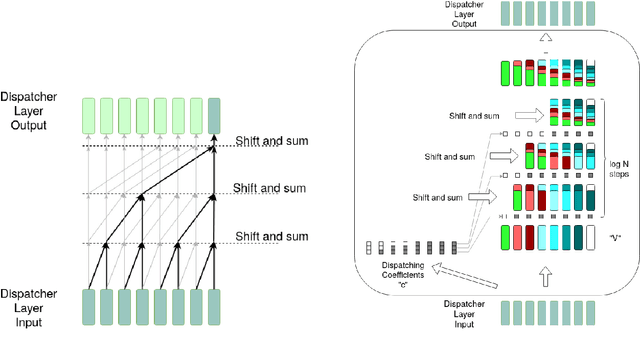
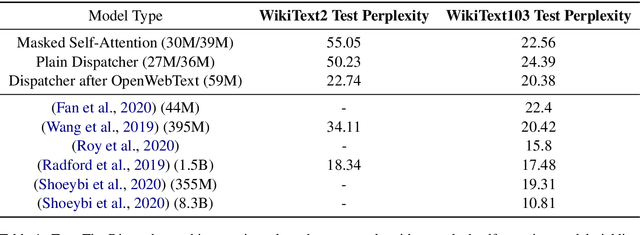
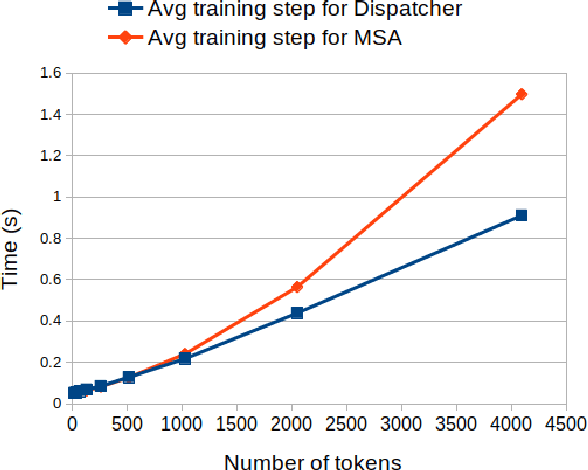
This paper proposes a message-passing mechanism to address language modelling. A new layer type is introduced that aims to substitute self-attention. The system is shown to be competitive with existing methods: Given N tokens, the computational complexity is O(N log N) and the memory complexity is O(N) under reasonable assumptions. In the end, the Dispatcher layer is seen to achieve comparable perplexity to prior results while being more efficient
View paper on