 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised learning for improving the accuracy of robot-mounted 3D camera applied to human gait analysis
Jul 03, 2022
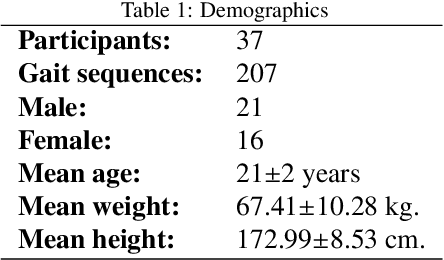


The use of 3D cameras for gait analysis has been highly questioned due to the low accuracy they have demonstrated in the past. The objective of the study presented in this paper is to improve the accuracy of the estimations made by robot-mounted 3D cameras in human gait analysis by applying a supervised learning stage. The 3D camera was mounted in a mobile robot to obtain a longer walking distance. This study shows an improvement in detection of kinematic gait signals and gait descriptors by post-processing the raw estimations of the camera using artificial neural networks trained with the data obtained from a certified Vicon system. To achieve this, 37 healthy participants were recruited and data of 207 gait sequences were collected using an Orbbec Astra 3D camera. There are two basic possible approaches for training: using kinematic gait signals and using gait descriptors. The former seeks to improve the waveforms of kinematic gait signals by reducing the error and increasing the correlation with respect to the Vicon system. The second is a more direct approach, focusing on training the artificial neural networks using gait descriptors directly. The accuracy of the 3D camera was measured before and after training. In both training approaches, an improvement was observed. Kinematic gait signals showed lower errors and higher correlations with respect to the ground truth. The accuracy of the system to detect gait descriptors also showed a substantial improvement, mostly for kinematic descriptors rather than spatio-temporal. When comparing both training approaches, it was not possible to define which was the absolute best. Therefore, we believe that the selection of the training approach will depend on the purpose of the study to be conducted. This study reveals the great potential of 3D cameras and encourages the research community to continue exploring their use in gait analysis.
Emotional Storytelling using Virtual and Robotic Agents
Jul 18, 2016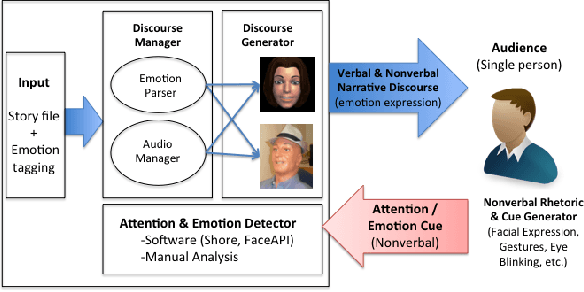

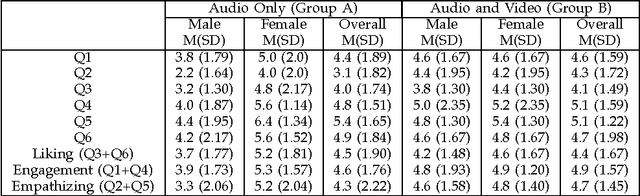
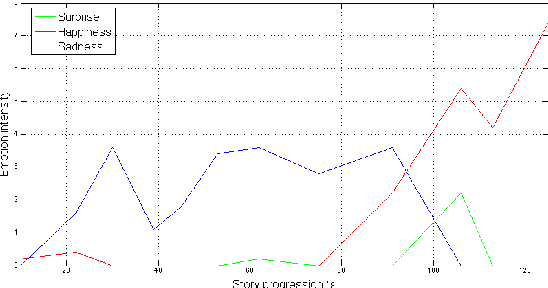
In order to create effective storytelling agents three fundamental questions must be answered: first, is a physically embodied agent preferable to a virtual agent or a voice-only narration? Second, does a human voice have an advantage over a synthesised voice? Third, how should the emotional trajectory of the different characters in a story be related to a storyteller's facial expressions during storytelling time, and how does this correlate with the apparent emotions on the faces of the listeners? The results of two specially designed studies indicate that the physically embodied robot produces more attention to the listener as compared to a virtual embodiment, that a human voice is preferable over the current state of the art of text-to-speech, and that there is a complex yet interesting relation between the emotion lines of the story, the facial expressions of the narrating agent, and the emotions of the listener, and that the empathising of the listener is evident through its facial expressions. This work constitutes an important step towards emotional storytelling robots that can observe their listeners and adapt their style in order to maximise their effectiveness.