Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating populations with wide data: A spectral analysis
Jan 29, 2009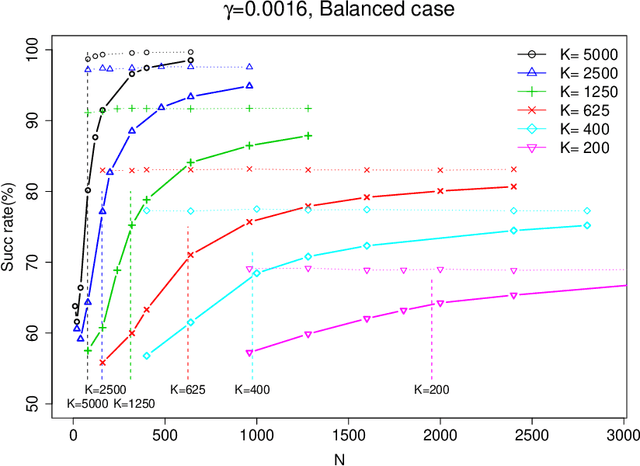
In this paper, we consider the problem of partitioning a small data sample drawn from a mixture of $k$ product distributions. We are interested in the case that individual features are of low average quality $\gamma$, and we want to use as few of them as possible to correctly partition the sample. We analyze a spectral technique that is able to approximately optimize the total data size--the product of number of data points $n$ and the number of features $K$--needed to correctly perform this partitioning as a function of $1/\gamma$ for $K>n$. Our goal is motivated by an application in clustering individuals according to their population of origin using markers, when the divergence between any two of the populations is small.
* Electronic Journal of Statistics 2009, Vol. 3, 76-113
* Published in at http://dx.doi.org/10.1214/08-EJS289 the Electronic Journal of Statistics (http://www.i-journals.org/ejs/) by the Institute of Mathematical Statistics (http://www.imstat.org)
* Published in at http://dx.doi.org/10.1214/08-EJS289 the Electronic Journal of Statistics (http://www.i-journals.org/ejs/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Via