 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUBO-inspired Molecular Fingerprint for Chemical Property Prediction
Mar 17, 2023Molecular fingerprints are widely used for predicting chemical properties, and selecting appropriate fingerprints is important. We generate new fingerprints based on the assumption that a performance of prediction using a more effective fingerprint is better. We generate effective interaction fingerprints that are the product of multiple base fingerprints. It is difficult to evaluate all combinations of interaction fingerprints because of computational limitations. Against this problem, we transform a problem of searching more effective interaction fingerprints into a quadratic unconstrained binary optimization problem. In this study, we found effective interaction fingerprints using QM9 dataset.
QUBO Decision Tree: Annealing Machine Extends Decision Tree Splitting
Mar 17, 2023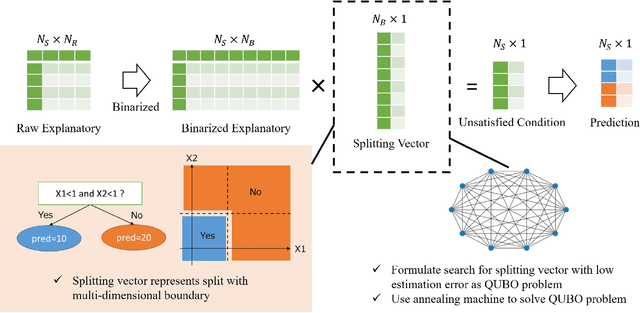
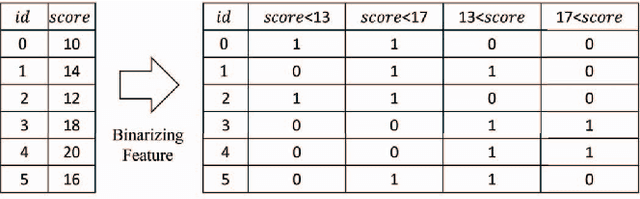
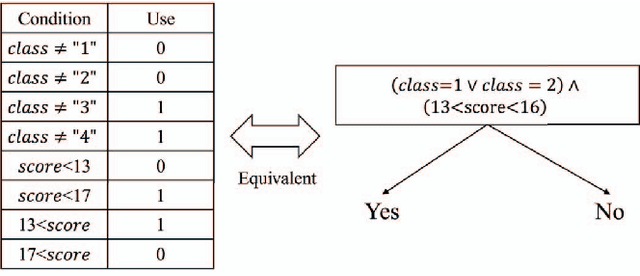
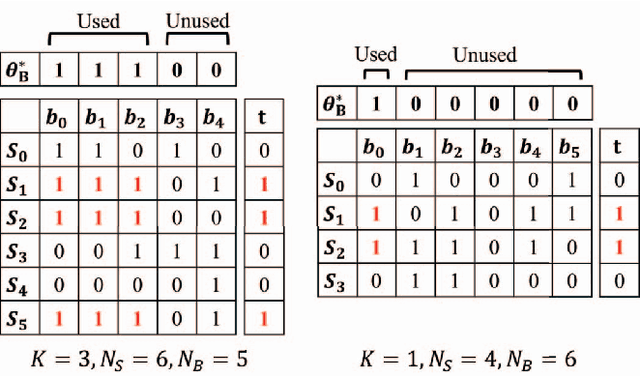
This paper proposes an extension of regression trees by quadratic unconstrained binary optimization (QUBO). Regression trees are very popular prediction models that are trainable with tabular datasets, but their accuracy is insufficient because the decision rules are too simple. The proposed method extends the decision rules in decision trees to multi-dimensional boundaries. Such an extension is generally unimplementable because of computational limitations, however, the proposed method transforms the training process to QUBO, which enables an annealing machine to solve this problem.
Proposing Novel Extrapolative Compounds by Nested Variational Autoencoders
Feb 06, 2023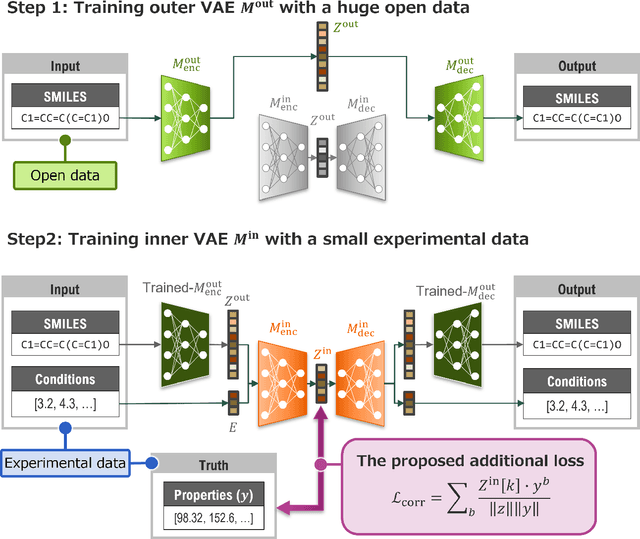

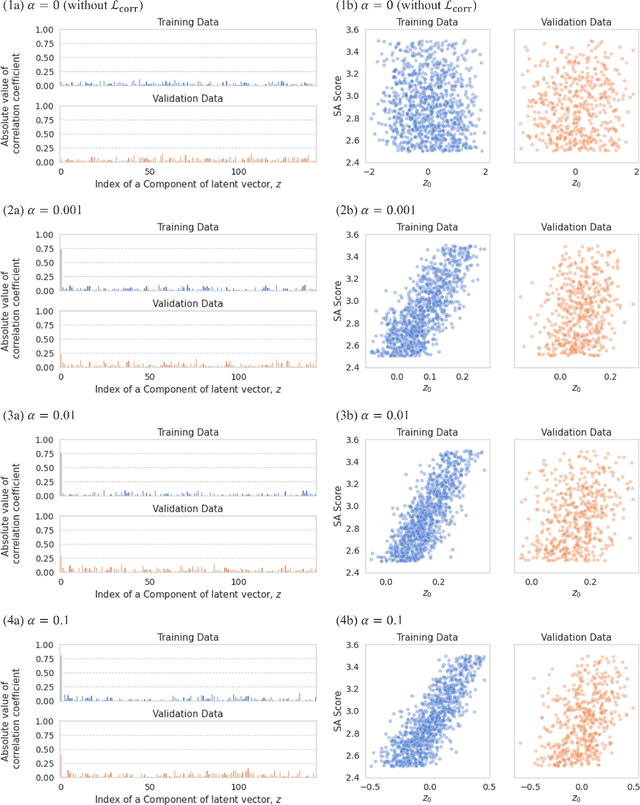
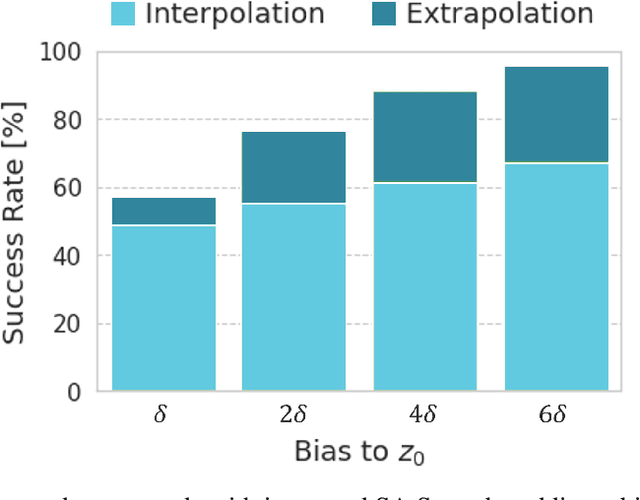
Materials informatics (MI), which uses artificial intelligence and data analysis techniques to improve the efficiency of materials development, is attracting increasing interest from industry. One of its main applications is the rapid development of new high-performance compounds. Recently, several deep generative models have been proposed to suggest candidate compounds that are expected to satisfy the desired performance. However, they usually have the problem of requiring a large amount of experimental datasets for training to achieve sufficient accuracy. In actual cases, it is often possible to accumulate only about 1000 experimental data at most. Therefore, the authors proposed a deep generative model with nested two variational autoencoders (VAEs). The outer VAE learns the structural features of compounds using large-scale public data, while the inner VAE learns the relationship between the latent variables of the outer VAE and the properties from small-scale experimental data. To generate high performance compounds beyond the range of the training data, the authors also proposed a loss function that amplifies the correlation between a component of latent variables of the inner VAE and material properties. The results indicated that this loss function contributes to improve the probability of generating high-performance candidates. Furthermore, as a result of verification test with an actual customer in chemical industry, it was confirmed that the proposed method is effective in reducing the number of experiments to $1/4$ compared to a conventional method.
Accelerating small-angle scattering experiments with simulation-based machine learning
Aug 24, 2019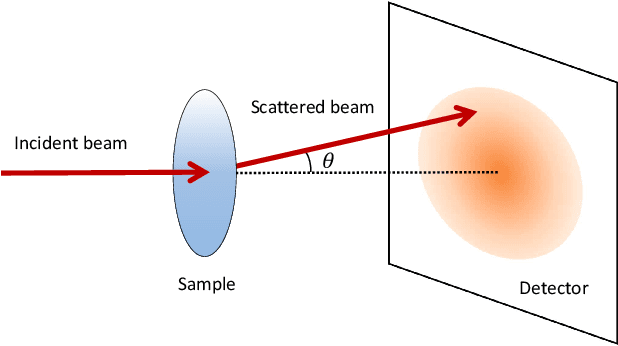

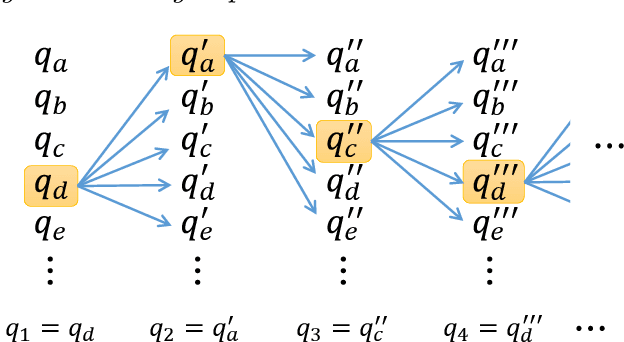
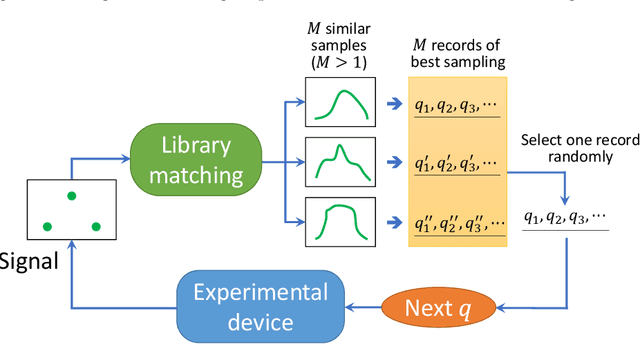
Making material experiments more efficient is a high priority for materials scientists who seek to discover new materials with desirable properties. In this paper, we investigate how to optimize the laborious sequential measurements of materials properties with data-driven methods, taking the small-angle neutron scattering (SANS) experiment as a test case. We propose two methods for optimizing sequential data sampling. These methods iteratively suggest the best target for the next measurement by performing a statistical analysis of the already acquired data, so that maximal information is gained at each step of an experiment. We conducted numerical simulations of SANS experiments for virtual materials and confirmed that the proposed methods significantly outperform baselines.