 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposing Novel Extrapolative Compounds by Nested Variational Autoencoders
Paper and Code
Feb 06, 2023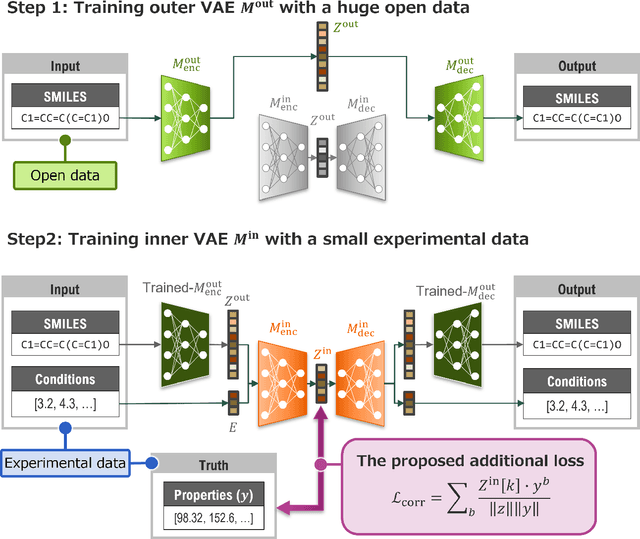

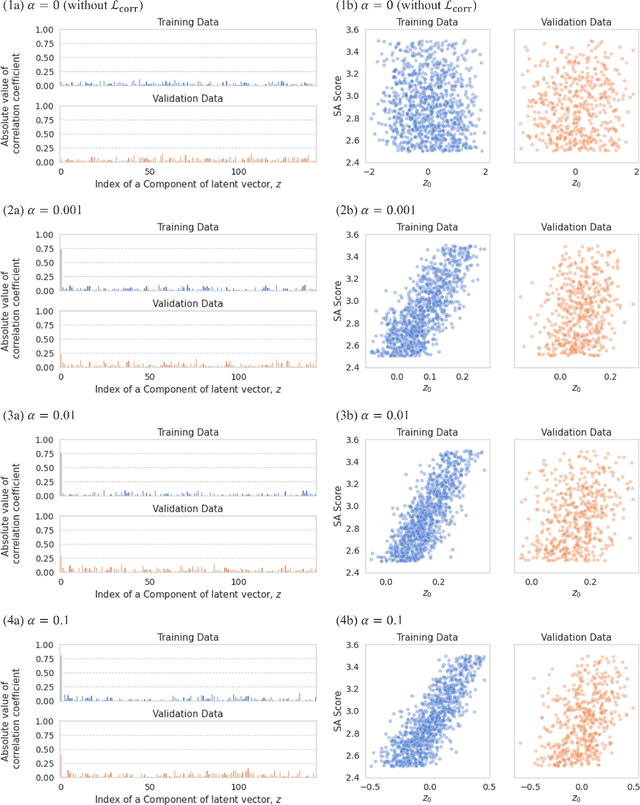
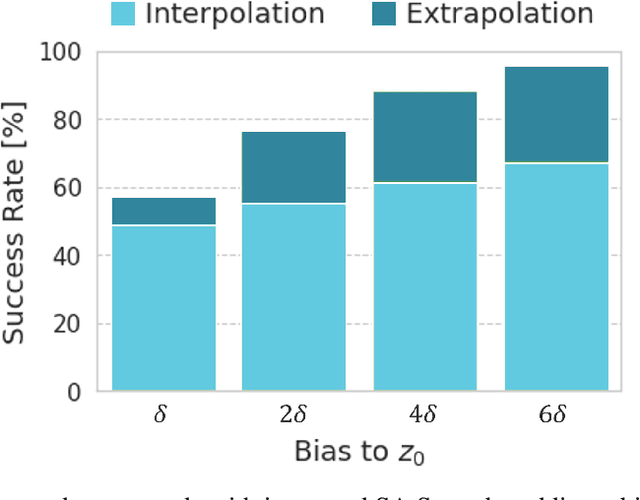
Materials informatics (MI), which uses artificial intelligence and data analysis techniques to improve the efficiency of materials development, is attracting increasing interest from industry. One of its main applications is the rapid development of new high-performance compounds. Recently, several deep generative models have been proposed to suggest candidate compounds that are expected to satisfy the desired performance. However, they usually have the problem of requiring a large amount of experimental datasets for training to achieve sufficient accuracy. In actual cases, it is often possible to accumulate only about 1000 experimental data at most. Therefore, the authors proposed a deep generative model with nested two variational autoencoders (VAEs). The outer VAE learns the structural features of compounds using large-scale public data, while the inner VAE learns the relationship between the latent variables of the outer VAE and the properties from small-scale experimental data. To generate high performance compounds beyond the range of the training data, the authors also proposed a loss function that amplifies the correlation between a component of latent variables of the inner VAE and material properties. The results indicated that this loss function contributes to improve the probability of generating high-performance candidates. Furthermore, as a result of verification test with an actual customer in chemical industry, it was confirmed that the proposed method is effective in reducing the number of experiments to $1/4$ compared to a conventional method.