 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLBInet: Radio Interferometry Data Classification for EHT with Neural Networks
Oct 14, 2021

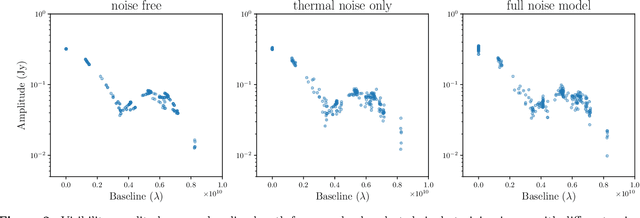
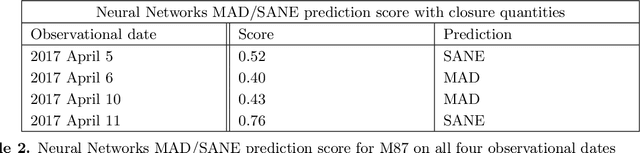
The Event Horizon Telescope (EHT) recently released the first horizon-scale images of the black hole in M87. Combined with other astronomical data, these images constrain the mass and spin of the hole as well as the accretion rate and magnetic flux trapped on the hole. An important question for the EHT is how well key parameters, such as trapped magnetic flux and the associated disk models, can be extracted from present and future EHT VLBI data products. The process of modeling visibilities and analyzing them is complicated by the fact that the data are sparsely sampled in the Fourier domain while most of the theory/simulation is constructed in the image domain. Here we propose a data-driven approach to analyze complex visibilities and closure quantities for radio interferometric data with neural networks. Using mock interferometric data, we show that our neural networks are able to infer the accretion state as either high magnetic flux (MAD) or low magnetic flux (SANE), suggesting that it is possible to perform parameter extraction directly in the visibility domain without image reconstruction. We have applied VLBInet to real M87 EHT data taken on four different days in 2017 (April 5, 6, 10, 11), and our neural networks give a score prediction 0.52, 0.4, 0.43, 0.76 for each day, with an average score 0.53, which shows no significant indication for the data to lean toward either the MAD or SANE state.
Rotate to Attend: Convolutional Triplet Attention Module
Oct 06, 2020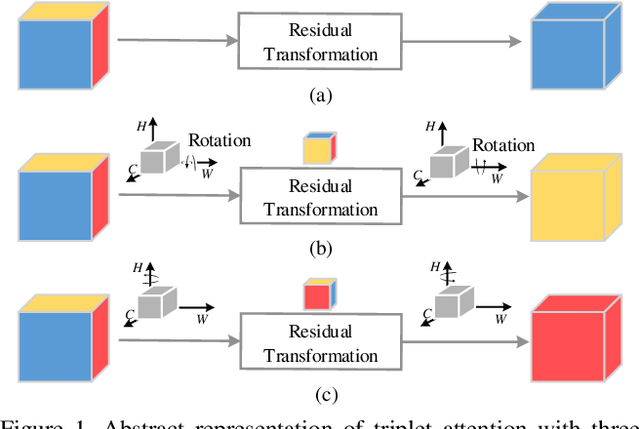

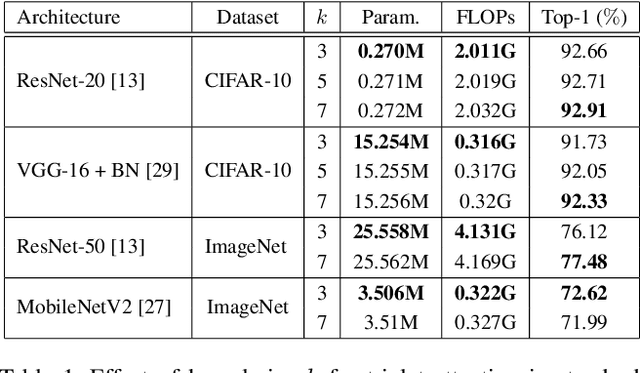
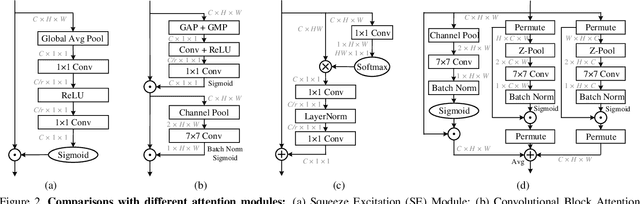
Benefiting from the capability of building inter-dependencies among channels or spatial locations, attention mechanisms have been extensively studied and broadly used in a variety of computer vision tasks recently. In this paper, we investigate light-weight but effective attention mechanisms and present triplet attention, a novel method for computing attention weights by capturing cross-dimension interaction using a three-branch structure. For an input tensor, triplet attention builds inter-dimensional dependencies by the rotation operation followed by residual transformations and encodes inter-channel and spatial information with negligible computational overhead. Our method is simple as well as efficient and can be easily plugged into classic backbone networks as an add-on module. We demonstrate the effectiveness of our method on various challenging tasks including image classification on ImageNet-1k and object detection on MSCOCO and PASCAL VOC datasets. Furthermore, we provide extensive in-sight into the performance of triplet attention by visually inspecting the GradCAM and GradCAM++ results. The empirical evaluation of our method supports our intuition on the importance of capturing dependencies across dimensions when computing attention weights. Code for this paper can be publicly accessed at https://github.com/LandskapeAI/triplet-attention