 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Differential Privacy through Posterior Sampling
Dec 23, 2016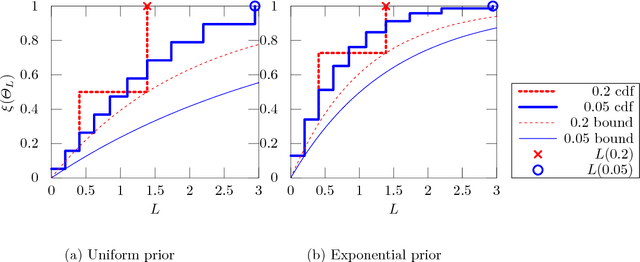
Differential privacy formalises privacy-preserving mechanisms that provide access to a database. We pose the question of whether Bayesian inference itself can be used directly to provide private access to data, with no modification. The answer is affirmative: under certain conditions on the prior, sampling from the posterior distribution can be used to achieve a desired level of privacy and utility. To do so, we generalise differential privacy to arbitrary dataset metrics, outcome spaces and distribution families. This allows us to also deal with non-i.i.d or non-tabular datasets. We prove bounds on the sensitivity of the posterior to the data, which gives a measure of robustness. We also show how to use posterior sampling to provide differentially private responses to queries, within a decision-theoretic framework. Finally, we provide bounds on the utility and on the distinguishability of datasets. The latter are complemented by a novel use of Le Cam's method to obtain lower bounds. All our general results hold for arbitrary database metrics, including those for the common definition of differential privacy. For specific choices of the metric, we give a number of examples satisfying our assumptions.
Statistical Decision Making for Authentication and Intrusion Detection
Oct 05, 2009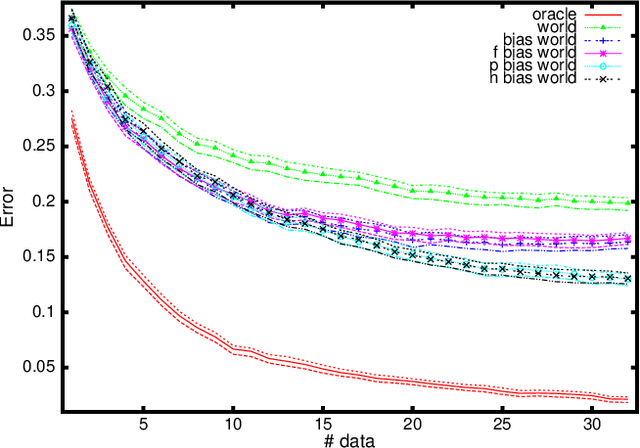
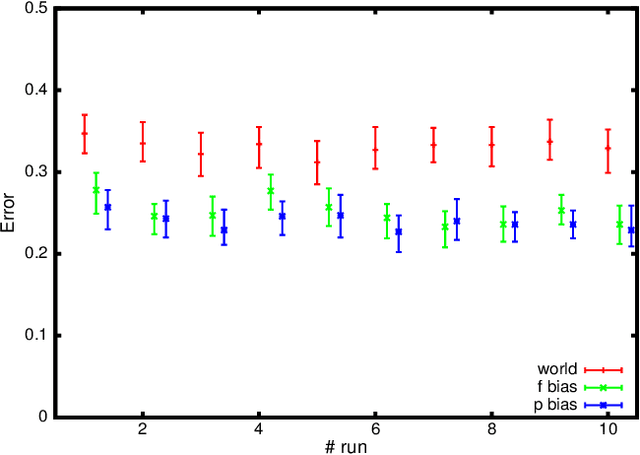
User authentication and intrusion detection differ from standard classification problems in that while we have data generated from legitimate users, impostor or intrusion data is scarce or non-existent. We review existing techniques for dealing with this problem and propose a novel alternative based on a principled statistical decision-making view point. We examine the technique on a toy problem and validate it on complex real-world data from an RFID based access control system. The results indicate that it can significantly outperform the classical world model approach. The method could be more generally useful in other decision-making scenarios where there is a lack of adversary data.
Intrusion Detection Using Cost-Sensitive Classification
Jul 13, 2008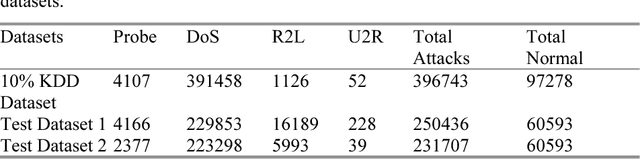
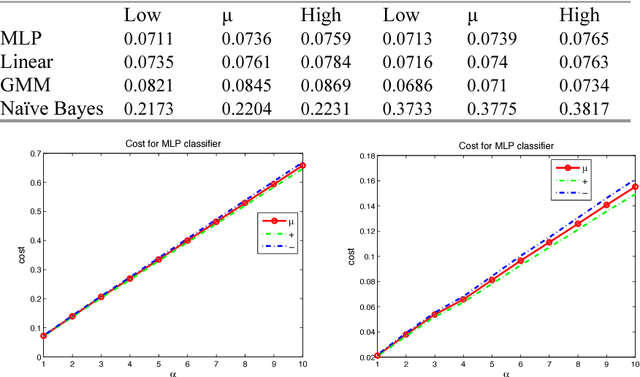

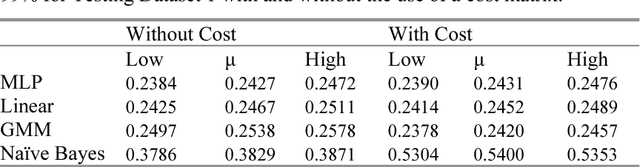
Intrusion Detection is an invaluable part of computer networks defense. An important consideration is the fact that raising false alarms carries a significantly lower cost than not detecting at- tacks. For this reason, we examine how cost-sensitive classification methods can be used in Intrusion Detection systems. The performance of the approach is evaluated under different experimental conditions, cost matrices and different classification models, in terms of expected cost, as well as detection and false alarm rates. We find that even under unfavourable conditions, cost-sensitive classification can improve performance significantly, if only slightly.