 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Masks to Pixels and Meaning: A New Taxonomy, Benchmark, and Metrics for VLM Image Tampering
Mar 20, 2026Existing tampering detection benchmarks largely rely on object masks, which severely misalign with the true edit signal: many pixels inside a mask are untouched or only trivially modified, while subtle yet consequential edits outside the mask are treated as natural. We reformulate VLM image tampering from coarse region labels to a pixel-grounded, meaning and language-aware task. First, we introduce a taxonomy spanning edit primitives (replace/remove/splice/inpaint/attribute/colorization, etc.) and their semantic class of tampered object, linking low-level changes to high-level understanding. Second, we release a new benchmark with per-pixel tamper maps and paired category supervision to evaluate detection and classification within a unified protocol. Third, we propose a training framework and evaluation metrics that quantify pixel-level correctness with localization to assess confidence or prediction on true edit intensity, and further measure tamper meaning understanding via semantics-aware classification and natural language descriptions for the predicted regions. We also re-evaluate the existing strong segmentation/localization baselines on recent strong tamper detectors and reveal substantial over- and under-scoring using mask-only metrics, and expose failure modes on micro-edits and off-mask changes. Our framework advances the field from masks to pixels, meanings and language descriptions, establishing a rigorous standard for tamper localization, semantic classification and description. Code and benchmark data are available at https://github.com/VILA-Lab/PIXAR.
Investigating the Challenges of Class Imbalance and Scale Variation in Object Detection in Aerial Images
Feb 05, 2022
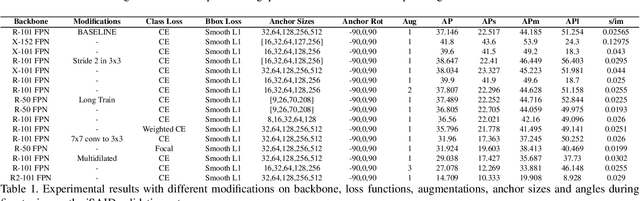
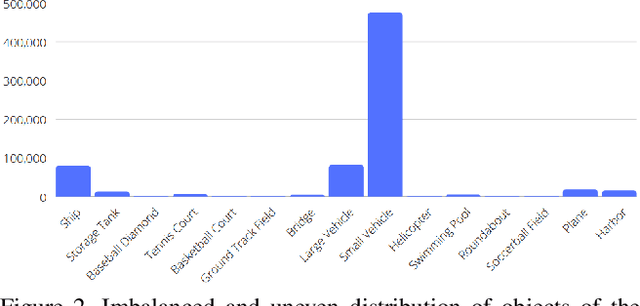
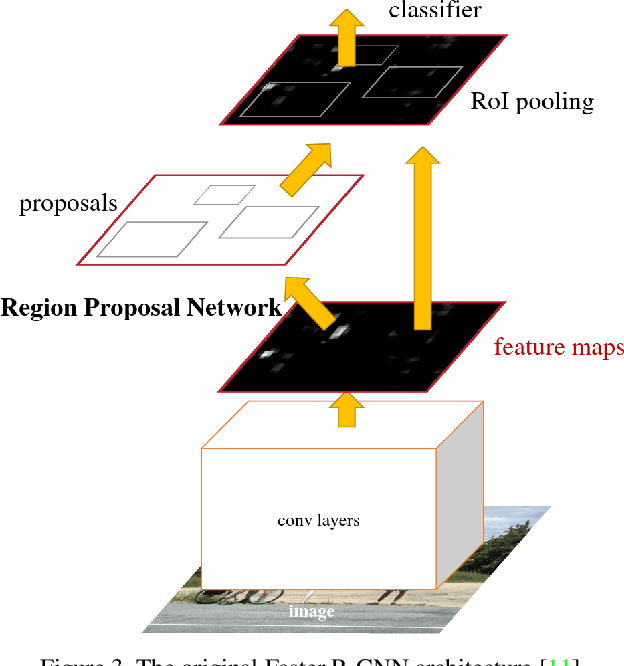
While object detection is a common problem in computer vision, it is even more challenging when dealing with aerial satellite images. The variety in object scales and orientations can make them difficult to identify. In addition, there can be large amounts of densely packed small objects such as cars. In this project, we propose a few changes to the Faster-RCNN architecture. First, we experiment with different backbones to extract better features. We also modify the data augmentations and generated anchor sizes for region proposals in order to better handle small objects. Finally, we investigate the effects of different loss functions. Our proposed design achieves an improvement of 4.7 mAP over the baseline which used a vanilla Faster R-CNN with a ResNet-101 FPN backbone.
Egyptian Sign Language Recognition Using CNN and LSTM
Jul 28, 2021
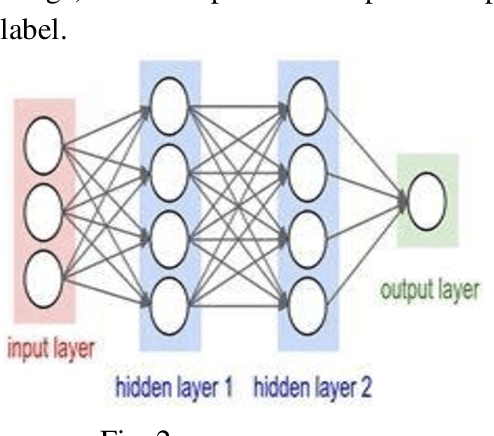
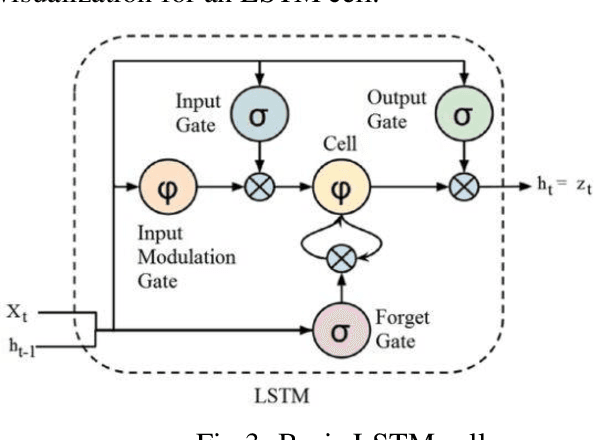
Sign language is a set of gestures that deaf people use to communicate. Unfortunately, normal people don't understand it, which creates a communication gap that needs to be filled. Because of the variations in (Egyptian Sign Language) ESL from one region to another, ESL provides a challenging research problem. In this work, we are providing applied research with its video-based Egyptian sign language recognition system that serves the local community of deaf people in Egypt, with a moderate and reasonable accuracy. We present a computer vision system with two different neural networks architectures. The first is a Convolutional Neural Network (CNN) for extracting spatial features. The CNN model was retrained on the inception mod. The second architecture is a CNN followed by a Long Short-Term Memory (LSTM) for extracting both spatial and temporal features. The two models achieved an accuracy of 90% and 72%, respectively. We examined the power of these two architectures to distinguish between 9 common words (with similar signs) among some deaf people community in Egypt.
Lighter Stacked Hourglass Human Pose Estimation
Jul 28, 2021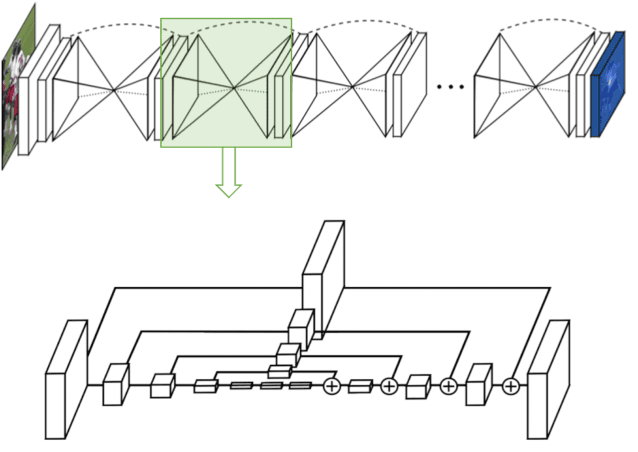
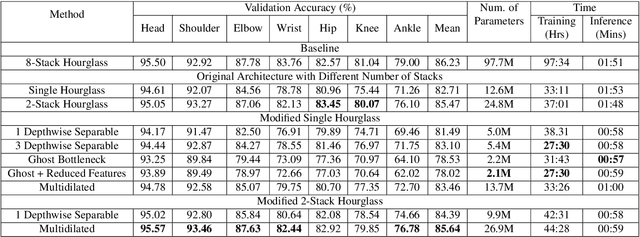
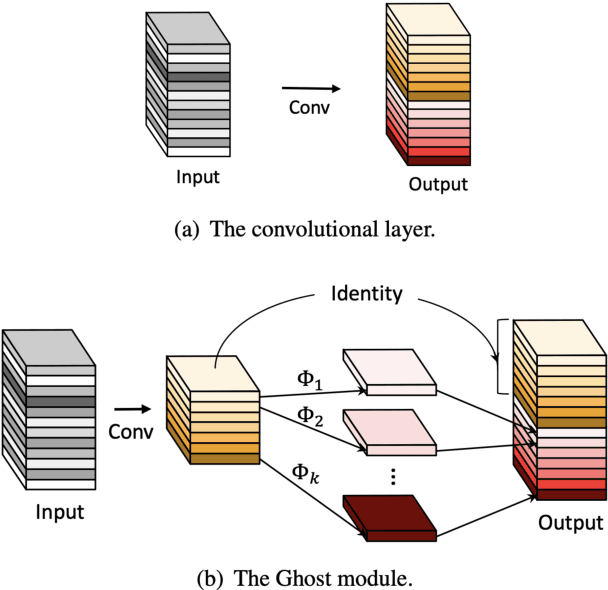
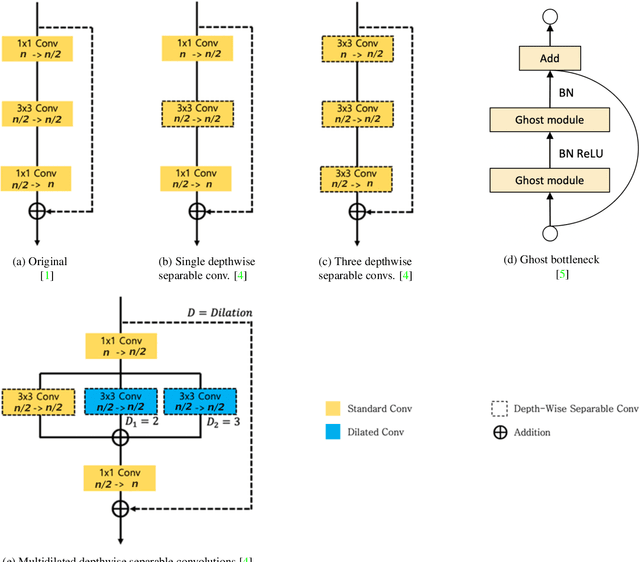
Human pose estimation (HPE) is one of the most challenging tasks in computer vision as humans are deformable by nature and thus their pose has so much variance. HPE aims to correctly identify the main joint locations of a single person or multiple people in a given image or video. Locating joints of a person in images or videos is an important task that can be applied in action recognition and object tracking. As have many computer vision tasks, HPE has advanced massively with the introduction of deep learning to the field. In this paper, we focus on one of the deep learning-based approaches of HPE proposed by Newell et al., which they named the stacked hourglass network. Their approach is widely used in many applications and is regarded as one of the best works in this area. The main focus of their approach is to capture as much information as it can at all possible scales so that a coherent understanding of the local features and full-body location is achieved. Their findings demonstrate that important cues such as orientation of a person, arrangement of limbs, and adjacent joints' relative location can be identified from multiple scales at different resolutions. To do so, they makes use of a single pipeline to process images in multiple resolutions, which comprises a skip layer to not lose spatial information at each resolution. The resolution of the images stretches as lower as 4x4 to make sure that a smaller spatial feature is included. In this study, we study the effect of architectural modifications on the computational speed and accuracy of the network.
A Thorough Review on Recent Deep Learning Methodologies for Image Captioning
Jul 28, 2021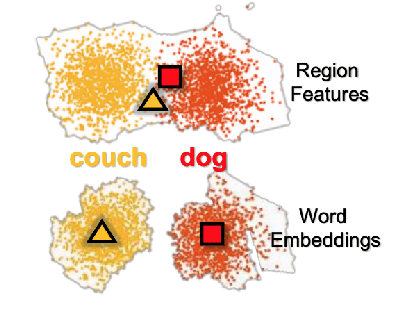
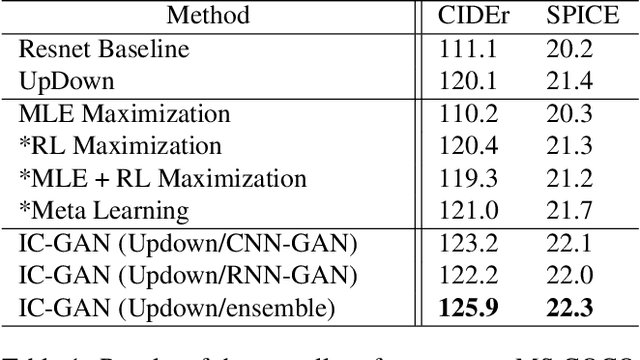
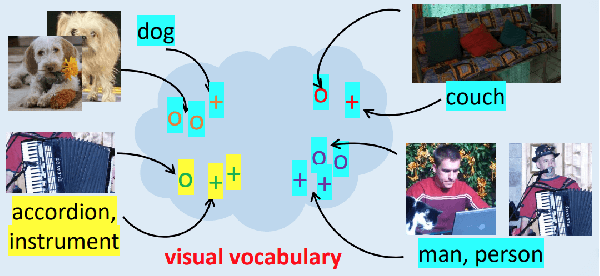
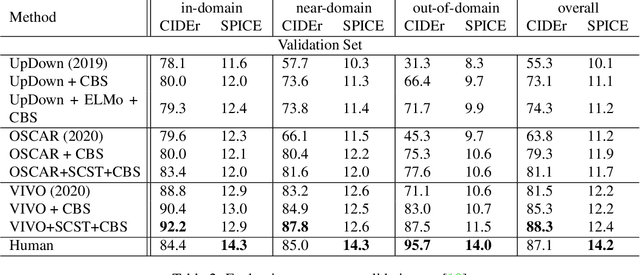
Image Captioning is a task that combines computer vision and natural language processing, where it aims to generate descriptive legends for images. It is a two-fold process relying on accurate image understanding and correct language understanding both syntactically and semantically. It is becoming increasingly difficult to keep up with the latest research and findings in the field of image captioning due to the growing amount of knowledge available on the topic. There is not, however, enough coverage of those findings in the available review papers. We perform in this paper a run-through of the current techniques, datasets, benchmarks and evaluation metrics used in image captioning. The current research on the field is mostly focused on deep learning-based methods, where attention mechanisms along with deep reinforcement and adversarial learning appear to be in the forefront of this research topic. In this paper, we review recent methodologies such as UpDown, OSCAR, VIVO, Meta Learning and a model that uses conditional generative adversarial nets. Although the GAN-based model achieves the highest score, UpDown represents an important basis for image captioning and OSCAR and VIVO are more useful as they use novel object captioning. This review paper serves as a roadmap for researchers to keep up to date with the latest contributions made in the field of image caption generation.
Experimenting with Self-Supervision using Rotation Prediction for Image Captioning
Jul 28, 2021

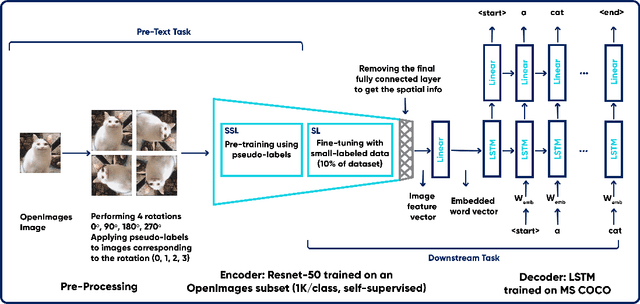

Image captioning is a task in the field of Artificial Intelligence that merges between computer vision and natural language processing. It is responsible for generating legends that describe images, and has various applications like descriptions used by assistive technology or indexing images (for search engines for instance). This makes it a crucial topic in AI that is undergoing a lot of research. This task however, like many others, is trained on large images labeled via human annotation, which can be very cumbersome: it needs manual effort, both financial and temporal costs, it is error-prone and potentially difficult to execute in some cases (e.g. medical images). To mitigate the need for labels, we attempt to use self-supervised learning, a type of learning where models use the data contained within the images themselves as labels. It is challenging to accomplish though, since the task is two-fold: the images and captions come from two different modalities and usually handled by different types of networks. It is thus not obvious what a completely self-supervised solution would look like. How it would achieve captioning in a comparable way to how self-supervision is applied today on image recognition tasks is still an ongoing research topic. In this project, we are using an encoder-decoder architecture where the encoder is a convolutional neural network (CNN) trained on OpenImages dataset and learns image features in a self-supervised fashion using the rotation pretext task. The decoder is a Long Short-Term Memory (LSTM), and it is trained, along within the image captioning model, on MS COCO dataset and is responsible of generating captions. Our GitHub repository can be found: https://github.com/elhagry1/SSL_ImageCaptioning_RotationPrediction