 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Challenges of Class Imbalance and Scale Variation in Object Detection in Aerial Images
Feb 05, 2022
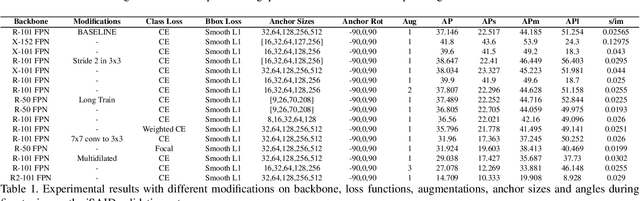
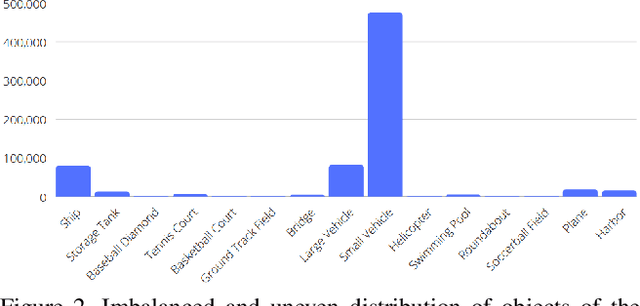
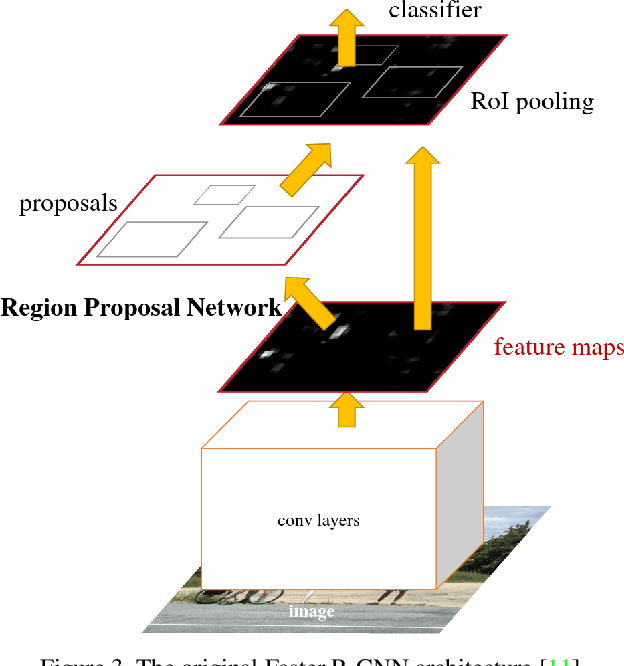
While object detection is a common problem in computer vision, it is even more challenging when dealing with aerial satellite images. The variety in object scales and orientations can make them difficult to identify. In addition, there can be large amounts of densely packed small objects such as cars. In this project, we propose a few changes to the Faster-RCNN architecture. First, we experiment with different backbones to extract better features. We also modify the data augmentations and generated anchor sizes for region proposals in order to better handle small objects. Finally, we investigate the effects of different loss functions. Our proposed design achieves an improvement of 4.7 mAP over the baseline which used a vanilla Faster R-CNN with a ResNet-101 FPN backbone.
Is Contrastive Learning Suitable for Left Ventricular Segmentation in Echocardiographic Images?
Jan 16, 2022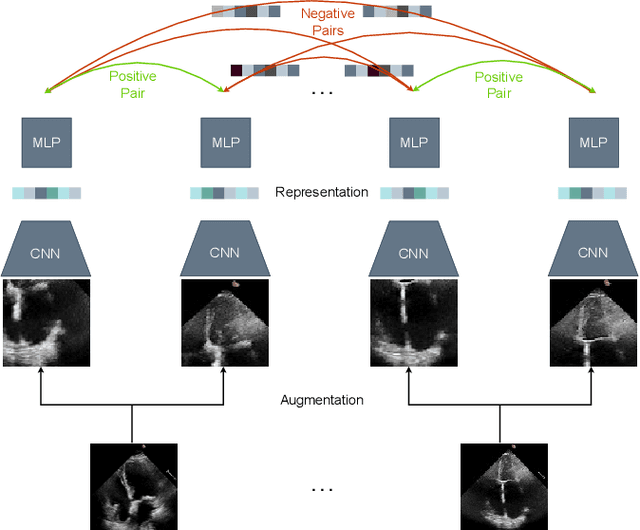
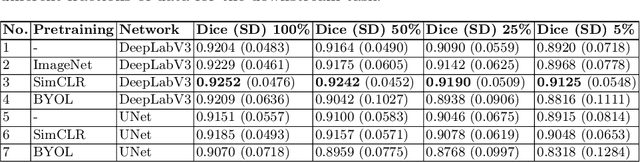
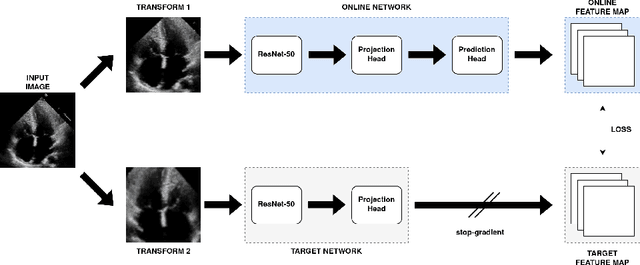
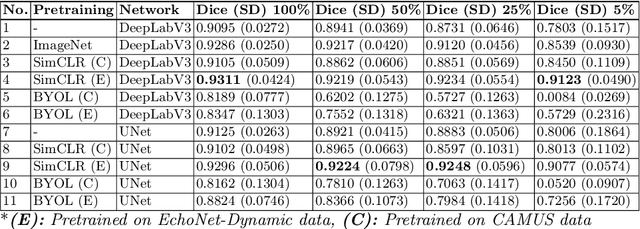
Contrastive learning has proven useful in many applications where access to labelled data is limited. The lack of annotated data is particularly problematic in medical image segmentation as it is difficult to have clinical experts manually annotate large volumes of data. One such task is the segmentation of cardiac structures in ultrasound images of the heart. In this paper, we argue whether or not contrastive pretraining is helpful for the segmentation of the left ventricle in echocardiography images. Furthermore, we study the effect of this on two segmentation networks, DeepLabV3, as well as the commonly used segmentation network, UNet. Our results show that contrastive pretraining helps improve the performance on left ventricle segmentation, particularly when annotated data is scarce. We show how to achieve comparable results to state-of-the-art fully supervised algorithms when we train our models in a self-supervised fashion followed by fine-tuning on just 5% of the data. We also show that our solution achieves better results than what is currently published on a large public dataset (EchoNet-Dynamic) and we compare the performance of our solution on another smaller dataset (CAMUS) as well.
Lighter Stacked Hourglass Human Pose Estimation
Jul 28, 2021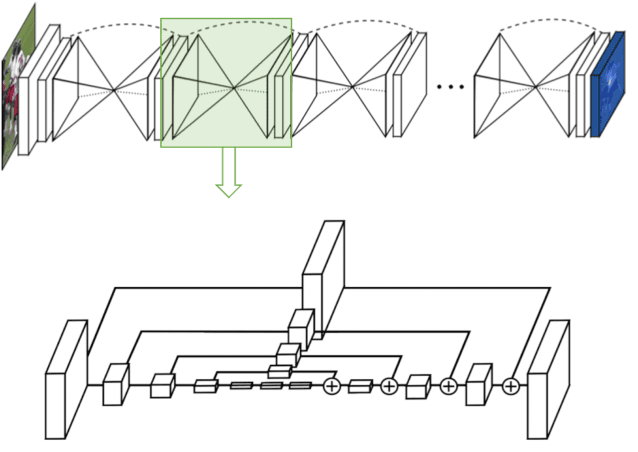
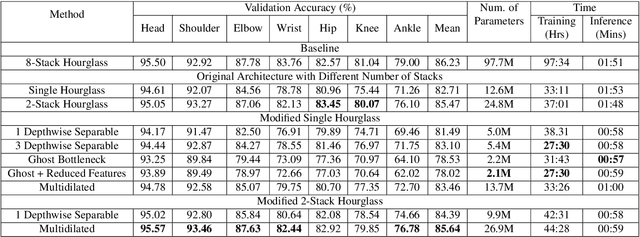
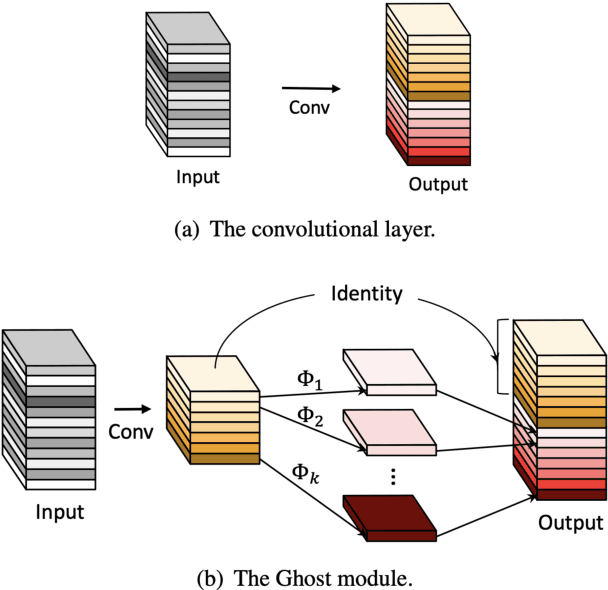
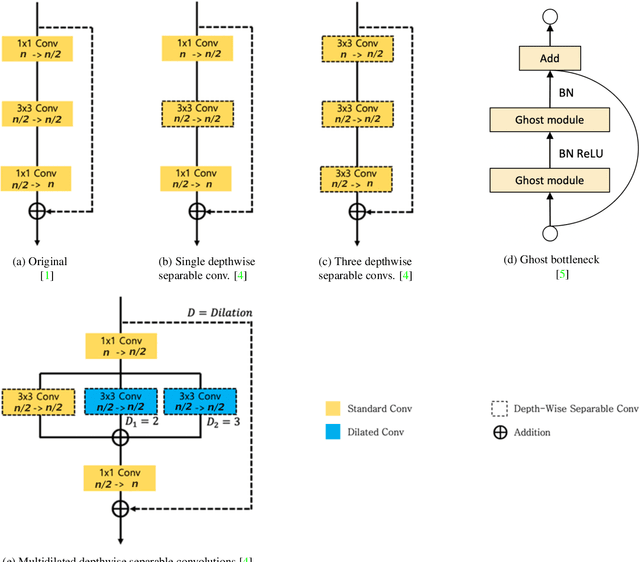
Human pose estimation (HPE) is one of the most challenging tasks in computer vision as humans are deformable by nature and thus their pose has so much variance. HPE aims to correctly identify the main joint locations of a single person or multiple people in a given image or video. Locating joints of a person in images or videos is an important task that can be applied in action recognition and object tracking. As have many computer vision tasks, HPE has advanced massively with the introduction of deep learning to the field. In this paper, we focus on one of the deep learning-based approaches of HPE proposed by Newell et al., which they named the stacked hourglass network. Their approach is widely used in many applications and is regarded as one of the best works in this area. The main focus of their approach is to capture as much information as it can at all possible scales so that a coherent understanding of the local features and full-body location is achieved. Their findings demonstrate that important cues such as orientation of a person, arrangement of limbs, and adjacent joints' relative location can be identified from multiple scales at different resolutions. To do so, they makes use of a single pipeline to process images in multiple resolutions, which comprises a skip layer to not lose spatial information at each resolution. The resolution of the images stretches as lower as 4x4 to make sure that a smaller spatial feature is included. In this study, we study the effect of architectural modifications on the computational speed and accuracy of the network.