 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoCoTr: Estimation of the Left Ventricular Ejection Fraction from Spatiotemporal Echocardiography
Sep 09, 2022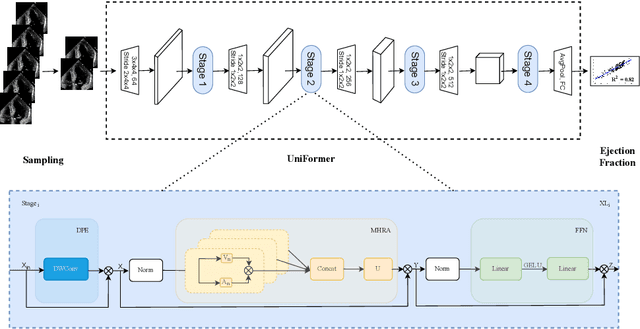
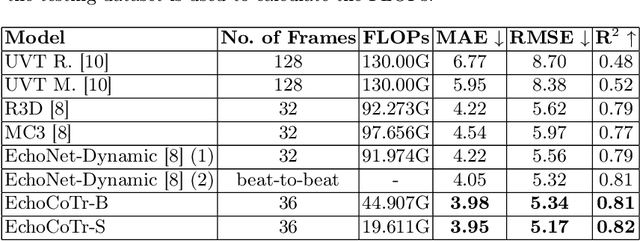
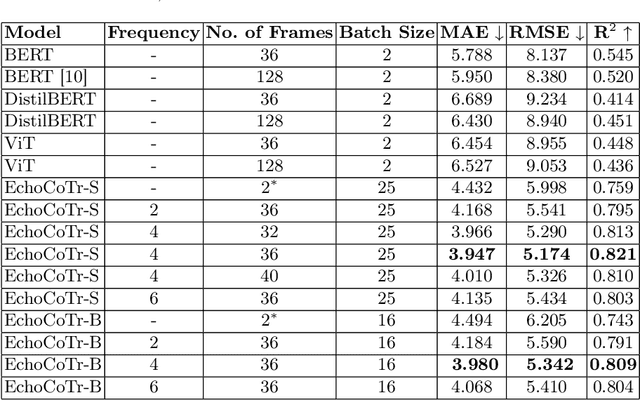
Learning spatiotemporal features is an important task for efficient video understanding especially in medical images such as echocardiograms. Convolutional neural networks (CNNs) and more recent vision transformers (ViTs) are the most commonly used methods with limitations per each. CNNs are good at capturing local context but fail to learn global information across video frames. On the other hand, vision transformers can incorporate global details and long sequences but are computationally expensive and typically require more data to train. In this paper, we propose a method that addresses the limitations we typically face when training on medical video data such as echocardiographic scans. The algorithm we propose (EchoCoTr) utilizes the strength of vision transformers and CNNs to tackle the problem of estimating the left ventricular ejection fraction (LVEF) on ultrasound videos. We demonstrate how the proposed method outperforms state-of-the-art work to-date on the EchoNet-Dynamic dataset with MAE of 3.95 and $R^2$ of 0.82. These results show noticeable improvement compared to all published research. In addition, we show extensive ablations and comparisons with several algorithms, including ViT and BERT. The code is available at https://github.com/BioMedIA-MBZUAI/EchoCoTr.
RADNet: Ensemble Model for Robust Glaucoma Classification in Color Fundus Images
May 25, 2022
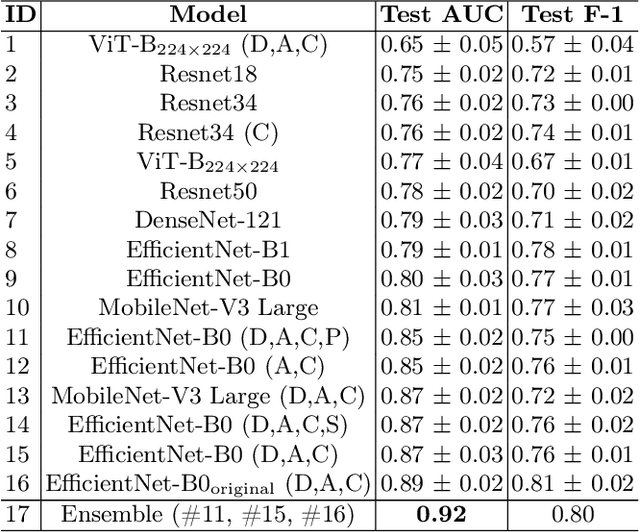
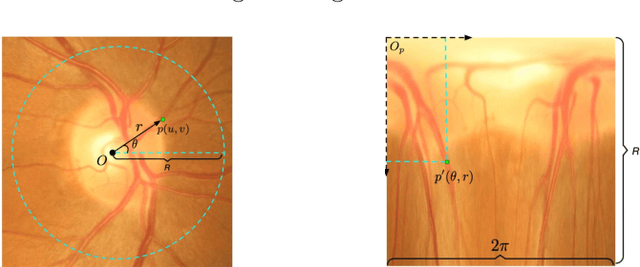
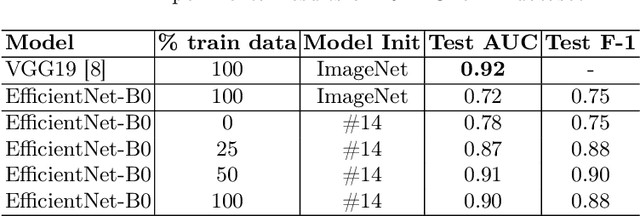
Glaucoma is one of the most severe eye diseases, characterized by rapid progression and leading to irreversible blindness. It is often the case that pathology diagnostics is carried out when the one's sight has already significantly degraded due to the lack of noticeable symptoms at early stage of the disease. Regular glaucoma screenings of the population shall improve early-stage detection, however the desirable frequency of etymological checkups is often not feasible due to excessive load imposed by manual diagnostics on limited number of specialists. Considering the basic methodology to detect glaucoma is to analyze fundus images for the \textit{optic-disc-to-optic-cup ratio}, Machine Learning domain can offer sophisticated tooling for image processing and classification. In our work, we propose an advanced image pre-processing technique combined with an ensemble of deep classification networks. Our \textit{Retinal Auto Detection (RADNet)} model has been successfully tested on Rotterdam EyePACS AIROGS train dataset with AUC of 0.92, and then additionally finetuned and tested on a fraction of RIM-ONE DL dataset with AUC of 0.91.
Is Contrastive Learning Suitable for Left Ventricular Segmentation in Echocardiographic Images?
Jan 16, 2022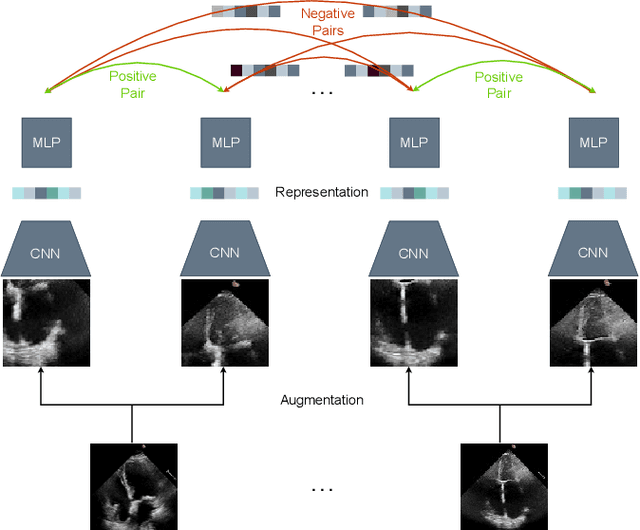
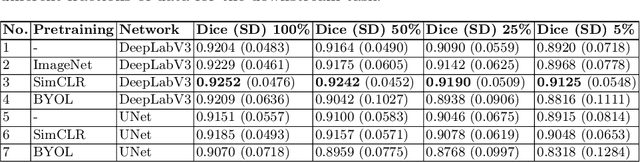
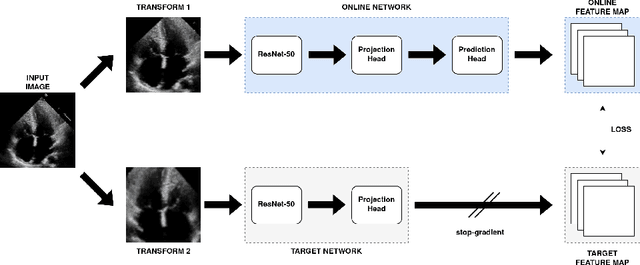
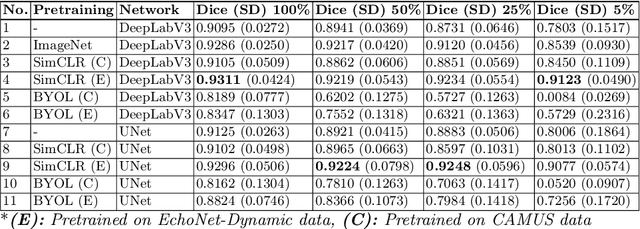
Contrastive learning has proven useful in many applications where access to labelled data is limited. The lack of annotated data is particularly problematic in medical image segmentation as it is difficult to have clinical experts manually annotate large volumes of data. One such task is the segmentation of cardiac structures in ultrasound images of the heart. In this paper, we argue whether or not contrastive pretraining is helpful for the segmentation of the left ventricle in echocardiography images. Furthermore, we study the effect of this on two segmentation networks, DeepLabV3, as well as the commonly used segmentation network, UNet. Our results show that contrastive pretraining helps improve the performance on left ventricle segmentation, particularly when annotated data is scarce. We show how to achieve comparable results to state-of-the-art fully supervised algorithms when we train our models in a self-supervised fashion followed by fine-tuning on just 5% of the data. We also show that our solution achieves better results than what is currently published on a large public dataset (EchoNet-Dynamic) and we compare the performance of our solution on another smaller dataset (CAMUS) as well.