 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoCoTr: Estimation of the Left Ventricular Ejection Fraction from Spatiotemporal Echocardiography
Paper and Code
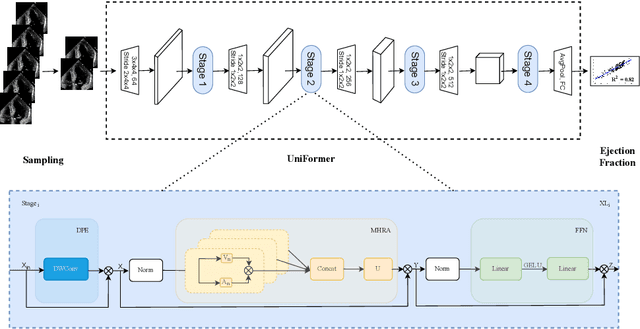
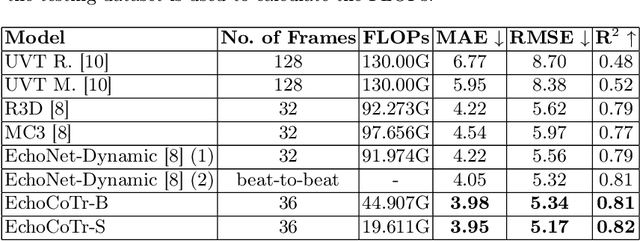
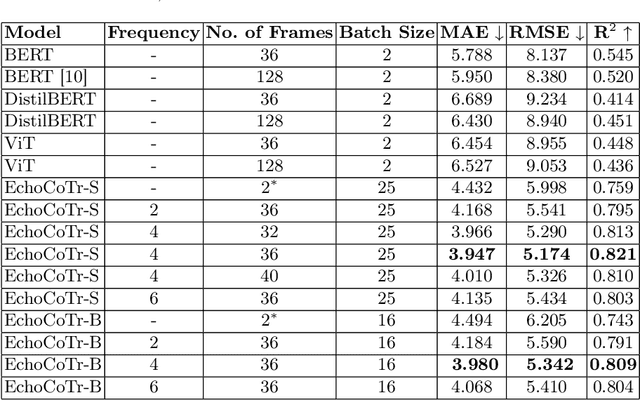
Learning spatiotemporal features is an important task for efficient video understanding especially in medical images such as echocardiograms. Convolutional neural networks (CNNs) and more recent vision transformers (ViTs) are the most commonly used methods with limitations per each. CNNs are good at capturing local context but fail to learn global information across video frames. On the other hand, vision transformers can incorporate global details and long sequences but are computationally expensive and typically require more data to train. In this paper, we propose a method that addresses the limitations we typically face when training on medical video data such as echocardiographic scans. The algorithm we propose (EchoCoTr) utilizes the strength of vision transformers and CNNs to tackle the problem of estimating the left ventricular ejection fraction (LVEF) on ultrasound videos. We demonstrate how the proposed method outperforms state-of-the-art work to-date on the EchoNet-Dynamic dataset with MAE of 3.95 and $R^2$ of 0.82. These results show noticeable improvement compared to all published research. In addition, we show extensive ablations and comparisons with several algorithms, including ViT and BERT. The code is available at https://github.com/BioMedIA-MBZUAI/EchoCoTr.