 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgyptian Sign Language Recognition Using CNN and LSTM
Jul 28, 2021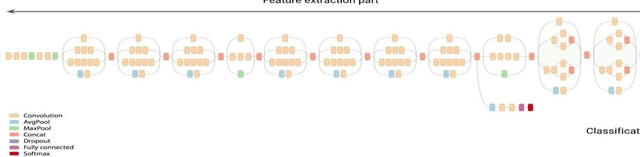
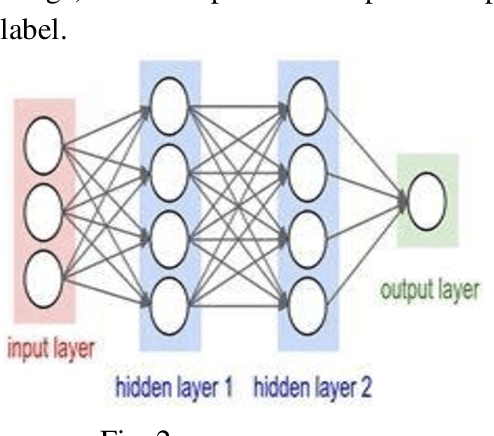
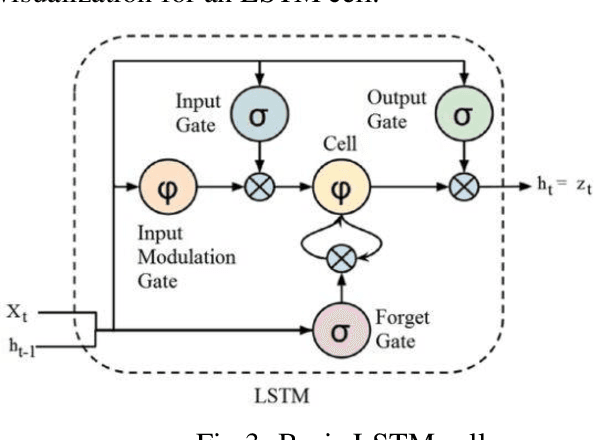
Sign language is a set of gestures that deaf people use to communicate. Unfortunately, normal people don't understand it, which creates a communication gap that needs to be filled. Because of the variations in (Egyptian Sign Language) ESL from one region to another, ESL provides a challenging research problem. In this work, we are providing applied research with its video-based Egyptian sign language recognition system that serves the local community of deaf people in Egypt, with a moderate and reasonable accuracy. We present a computer vision system with two different neural networks architectures. The first is a Convolutional Neural Network (CNN) for extracting spatial features. The CNN model was retrained on the inception mod. The second architecture is a CNN followed by a Long Short-Term Memory (LSTM) for extracting both spatial and temporal features. The two models achieved an accuracy of 90% and 72%, respectively. We examined the power of these two architectures to distinguish between 9 common words (with similar signs) among some deaf people community in Egypt.