 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Thorough Review on Recent Deep Learning Methodologies for Image Captioning
Paper and Code
Jul 28, 2021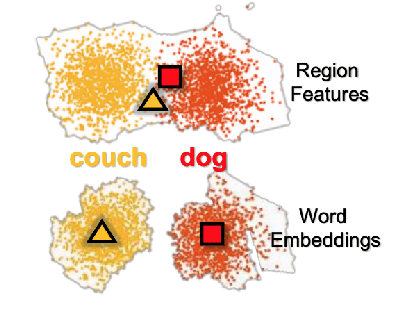
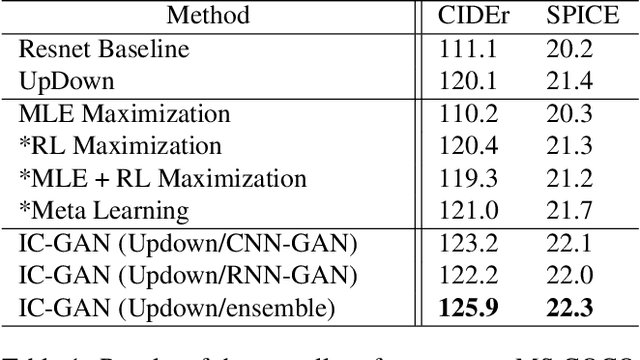
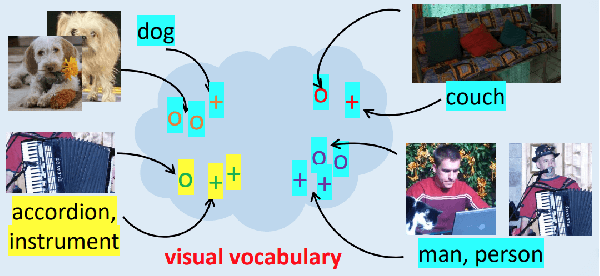
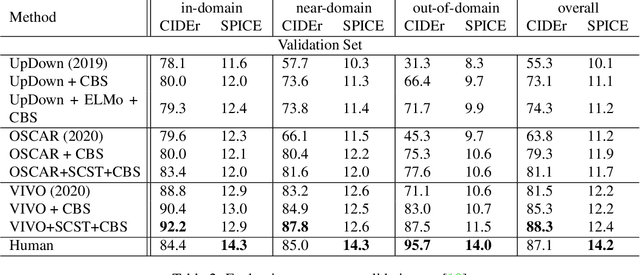
Image Captioning is a task that combines computer vision and natural language processing, where it aims to generate descriptive legends for images. It is a two-fold process relying on accurate image understanding and correct language understanding both syntactically and semantically. It is becoming increasingly difficult to keep up with the latest research and findings in the field of image captioning due to the growing amount of knowledge available on the topic. There is not, however, enough coverage of those findings in the available review papers. We perform in this paper a run-through of the current techniques, datasets, benchmarks and evaluation metrics used in image captioning. The current research on the field is mostly focused on deep learning-based methods, where attention mechanisms along with deep reinforcement and adversarial learning appear to be in the forefront of this research topic. In this paper, we review recent methodologies such as UpDown, OSCAR, VIVO, Meta Learning and a model that uses conditional generative adversarial nets. Although the GAN-based model achieves the highest score, UpDown represents an important basis for image captioning and OSCAR and VIVO are more useful as they use novel object captioning. This review paper serves as a roadmap for researchers to keep up to date with the latest contributions made in the field of image caption generation.