 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Foundational Models: Their Role in Anomaly Detection and Prediction
Dec 26, 2024Time series foundational models (TSFM) have gained prominence in time series forecasting, promising state-of-the-art performance across various applications. However, their application in anomaly detection and prediction remains underexplored, with growing concerns regarding their black-box nature, lack of interpretability and applicability. This paper critically evaluates the efficacy of TSFM in anomaly detection and prediction tasks. We systematically analyze TSFM across multiple datasets, including those characterized by the absence of discernible patterns, trends and seasonality. Our analysis shows that while TSFMs can be extended for anomaly detection and prediction, traditional statistical and deep learning models often match or outperform TSFM in these tasks. Additionally, TSFMs require high computational resources but fail to capture sequential dependencies effectively or improve performance in few-shot or zero-shot scenarios. \noindent The preprocessed datasets, codes to reproduce the results and supplementary materials are available at https://github.com/smtmnfg/TSFM.
Generating Knowledge Graphs from Large Language Models: A Comparative Study of GPT-4, LLaMA 2, and BERT
Dec 10, 2024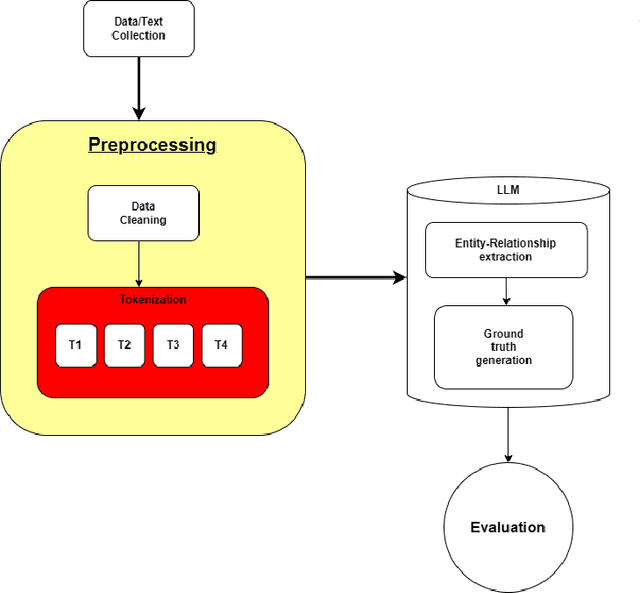
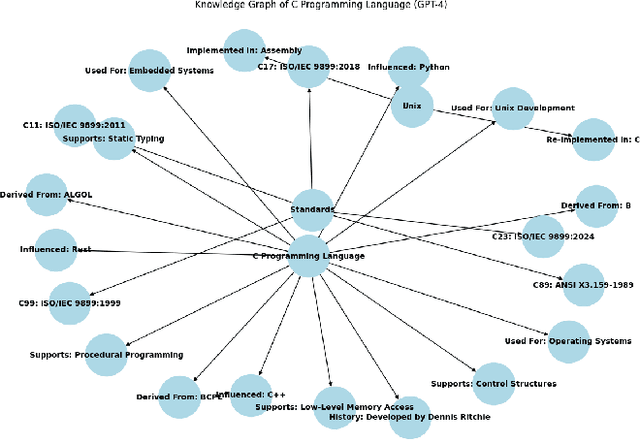
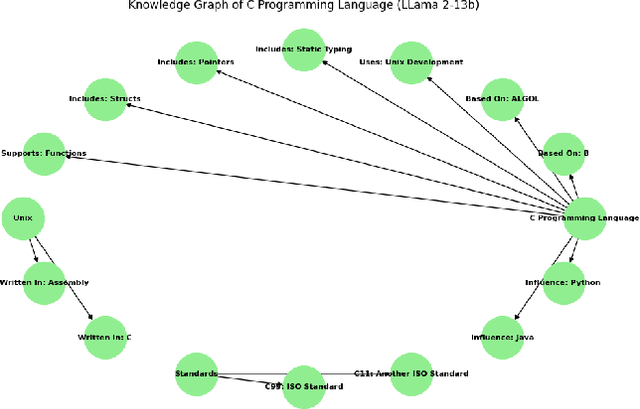
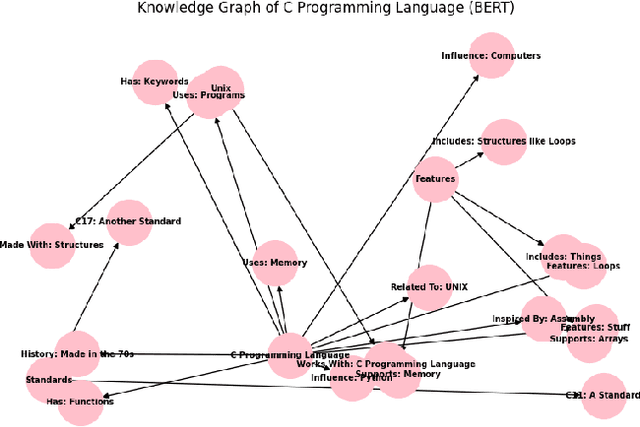
Knowledge Graphs (KGs) are essential for the functionality of GraphRAGs, a form of Retrieval-Augmented Generative Systems (RAGs) that excel in tasks requiring structured reasoning and semantic understanding. However, creating KGs for GraphRAGs remains a significant challenge due to accuracy and scalability limitations of traditional methods. This paper introduces a novel approach leveraging large language models (LLMs) like GPT-4, LLaMA 2 (13B), and BERT to generate KGs directly from unstructured data, bypassing traditional pipelines. Using metrics such as Precision, Recall, F1-Score, Graph Edit Distance, and Semantic Similarity, we evaluate the models' ability to generate high-quality KGs. Results demonstrate that GPT-4 achieves superior semantic fidelity and structural accuracy, LLaMA 2 excels in lightweight, domain-specific graphs, and BERT provides insights into challenges in entity-relationship modeling. This study underscores the potential of LLMs to streamline KG creation and enhance GraphRAG accessibility for real-world applications, while setting a foundation for future advancements.
Med-Bot: An AI-Powered Assistant to Provide Accurate and Reliable Medical Information
Nov 14, 2024


This paper introduces Med-Bot, an AI-powered chatbot designed to provide users with accurate and reliable medical information. Utilizing advanced libraries and frameworks such as PyTorch, Chromadb, Langchain and Autogptq, Med-Bot is built to handle the complexities of natural language understanding in a healthcare context. The integration of llamaassisted data processing and AutoGPT-Q provides enhanced performance in processing and responding to queries based on PDFs of medical literature, ensuring that users receive precise and trustworthy information. This research details the methodologies employed in developing Med-Bot and evaluates its effectiveness in disseminating healthcare information.
Leveraging LSTM for Predictive Modeling of Satellite Clock Bias
Nov 11, 2024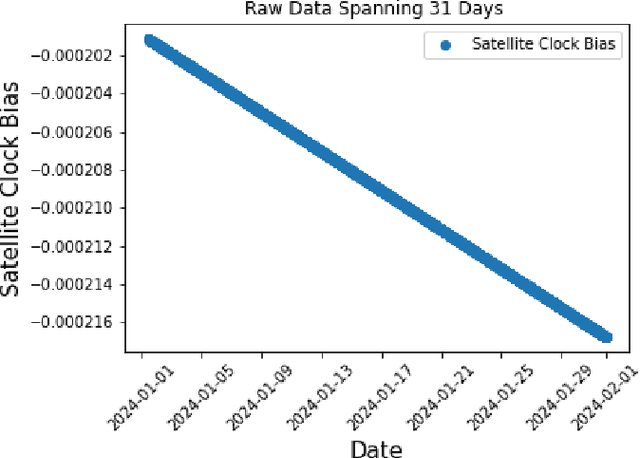
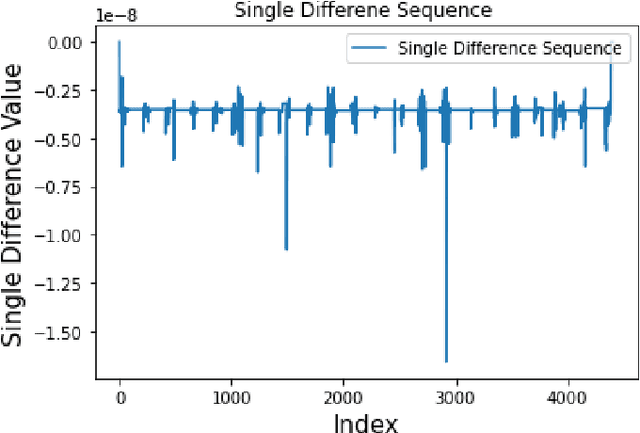
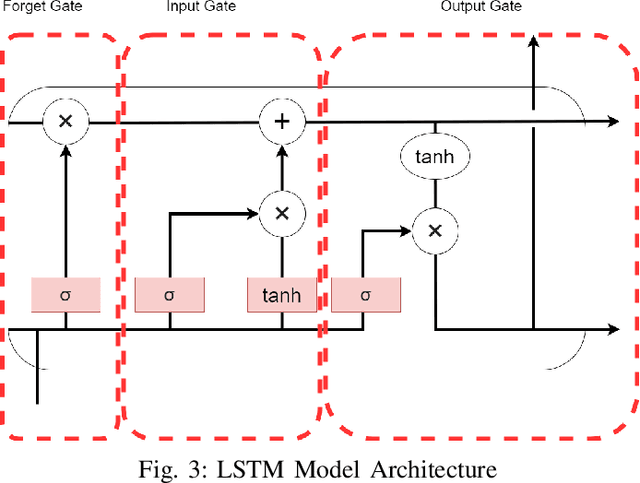
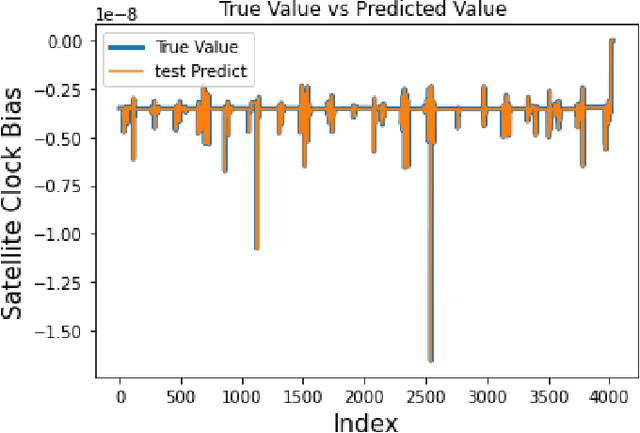
Satellite clock bias prediction plays a crucial role in enhancing the accuracy of satellite navigation systems. In this paper, we propose an approach utilizing Long Short-Term Memory (LSTM) networks to predict satellite clock bias. We gather data from the PRN 8 satellite of the Galileo and preprocess it to obtain a single difference sequence, crucial for normalizing the data. Normalization allows resampling of the data, ensuring that the predictions are equidistant and complete. Our methodology involves training the LSTM model on varying lengths of datasets, ranging from 7 days to 31 days. We employ a training set consisting of two days' worth of data in each case. Our LSTM model exhibits exceptional accuracy, with a Root Mean Square Error (RMSE) of 2.11 $\times$ 10$^{-11}$. Notably, our approach outperforms traditional methods used for similar time-series forecasting projects, being 170 times more accurate than RNN, 2.3 $\times$ 10$^7$ times more accurate than MLP, and 1.9 $\times$ 10$^4$ times more accurate than ARIMA. This study holds significant potential in enhancing the accuracy and efficiency of low-power receivers used in various devices, particularly those requiring power conservation. By providing more accurate predictions of satellite clock bias, the findings of this research can be integrated into the algorithms of such devices, enabling them to function with heightened precision while conserving power. Improved accuracy in clock bias predictions ensures that low-power receivers can maintain optimal performance levels, thereby enhancing the overall reliability and effectiveness of satellite navigation systems. Consequently, this advancement holds promise for a wide range of applications, including remote areas, IoT devices, wearable technology, and other devices where power efficiency and navigation accuracy are paramount.