 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid approach to detecting symptoms of depression in social media entries
Jun 19, 2021
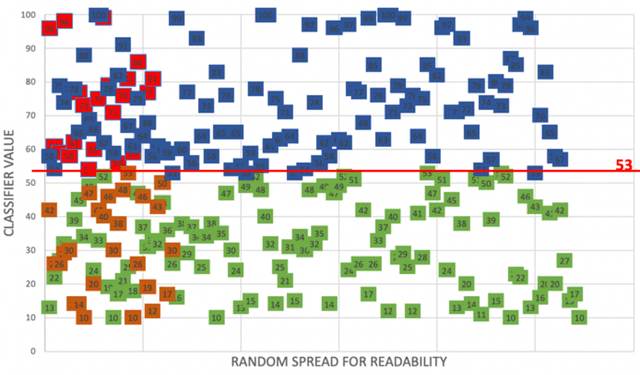
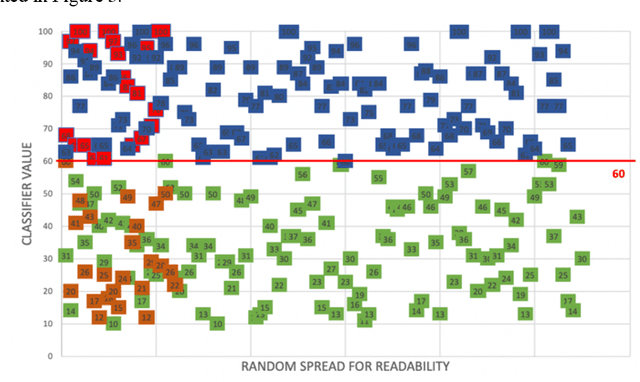

Sentiment and lexical analyses are widely used to detect depression or anxiety disorders. It has been documented that there are significant differences in the language used by a person with emotional disorders in comparison to a healthy individual. Still, the effectiveness of these lexical approaches could be improved further because the current analysis focuses on what the social media entries are about, and not how they are written. In this study, we focus on aspects in which these short texts are similar to each other, and how they were created. We present an innovative approach to the depression screening problem by applying Collgram analysis, which is a known effective method of obtaining linguistic information from texts. We compare these results with sentiment analysis based on the BERT architecture. Finally, we create a hybrid model achieving a diagnostic accuracy of 71%.
Enhancements in statistical spoken language translation by de-normalization of ASR results
Nov 18, 2015
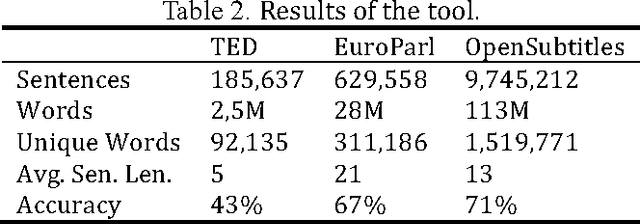
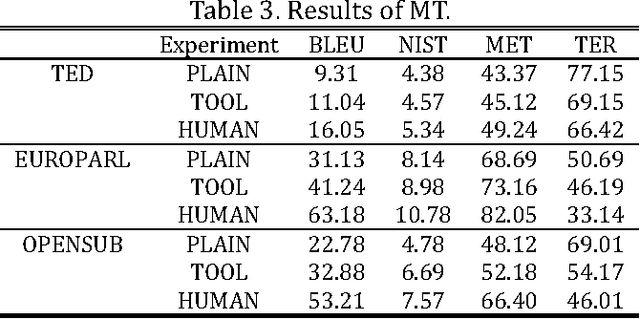
Spoken language translation (SLT) has become very important in an increasingly globalized world. Machine translation (MT) for automatic speech recognition (ASR) systems is a major challenge of great interest. This research investigates that automatic sentence segmentation of speech that is important for enriching speech recognition output and for aiding downstream language processing. This article focuses on the automatic sentence segmentation of speech and improving MT results. We explore the problem of identifying sentence boundaries in the transcriptions produced by automatic speech recognition systems in the Polish language. We also experiment with reverse normalization of the recognized speech samples.
* International Academy Publishing. arXiv admin note: text overlap with arXiv:1510.04500