 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid approach to detecting symptoms of depression in social media entries
Jun 19, 2021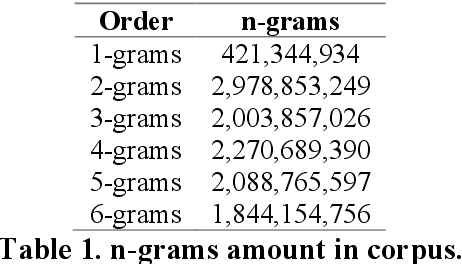
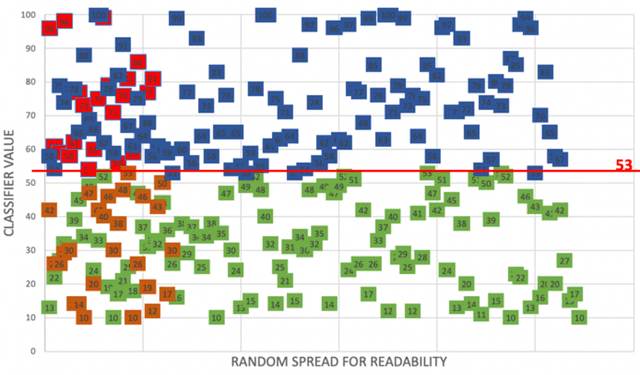
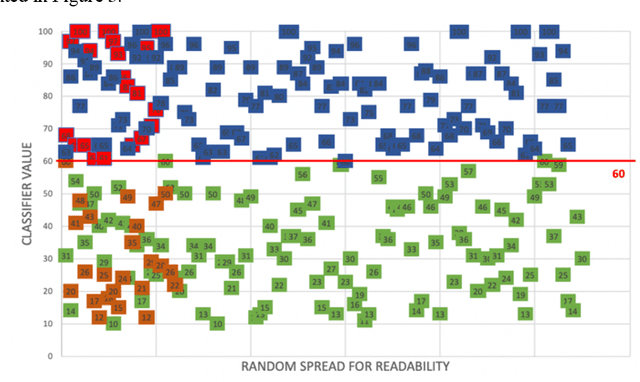

Sentiment and lexical analyses are widely used to detect depression or anxiety disorders. It has been documented that there are significant differences in the language used by a person with emotional disorders in comparison to a healthy individual. Still, the effectiveness of these lexical approaches could be improved further because the current analysis focuses on what the social media entries are about, and not how they are written. In this study, we focus on aspects in which these short texts are similar to each other, and how they were created. We present an innovative approach to the depression screening problem by applying Collgram analysis, which is a known effective method of obtaining linguistic information from texts. We compare these results with sentiment analysis based on the BERT architecture. Finally, we create a hybrid model achieving a diagnostic accuracy of 71%.
Automated speech-based screening of depression using deep convolutional neural networks
Dec 02, 2019


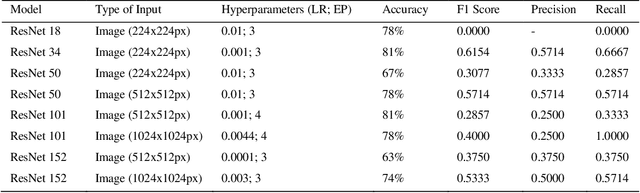
Early detection and treatment of depression is essential in promoting remission, preventing relapse, and reducing the emotional burden of the disease. Current diagnoses are primarily subjective, inconsistent across professionals, and expensive for individuals who may be in urgent need of help. This paper proposes a novel approach to automated depression detection in speech using convolutional neural network (CNN) and multipart interactive training. The model was tested using 2568 voice samples obtained from 77 non-depressed and 30 depressed individuals. In experiment conducted, data were applied to residual CNNs in the form of spectrograms, images auto-generated from audio samples. The experimental results obtained using different ResNet architectures gave a promising baseline accuracy reaching 77%.
Sentiment analysis model for Twitter data in Polish language
Nov 03, 2019Text mining analysis of tweets gathered during Polish presidential election on May 10th, 2015. The project included implementation of engine to retrieve information from Twitter, building document corpora, corpora cleaning, and creating Term-Document Matrix. Each tweet from the text corpora was assigned a category based on its sentiment score. The score was calculated using the number of positive and/or negative emoticons and Polish words in each document. The result data set was used to train and test four machine learning classifiers, to select these providing most accurate automatic tweet classification results. The Naive Bayes and Maximum Entropy algorithms achieved the best accuracy of respectively 71.76% and 77.32%. All implementation tasks were completed using R programming language.