 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Generalization in Audio Deepfake Detection: A Neural Collapse based Sampling and Training Approach
Apr 19, 2024
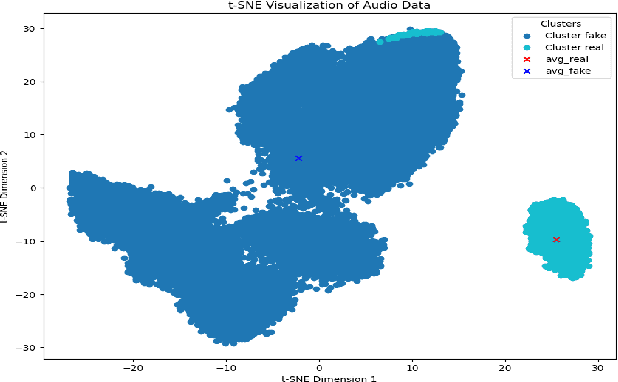

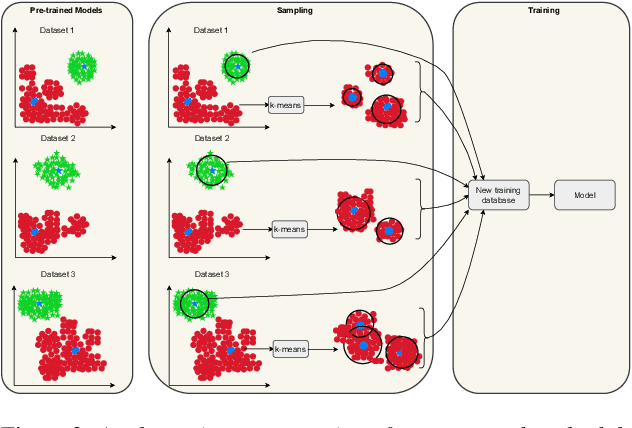
Generalization in audio deepfake detection presents a significant challenge, with models trained on specific datasets often struggling to detect deepfakes generated under varying conditions and unknown algorithms. While collectively training a model using diverse datasets can enhance its generalization ability, it comes with high computational costs. To address this, we propose a neural collapse-based sampling approach applied to pre-trained models trained on distinct datasets to create a new training database. Using ASVspoof 2019 dataset as a proof-of-concept, we implement pre-trained models with Resnet and ConvNext architectures. Our approach demonstrates comparable generalization on unseen data while being computationally efficient, requiring less training data. Evaluation is conducted using the In-the-wild dataset.
Towards the Development of a Real-Time Deepfake Audio Detection System in Communication Platforms
Mar 18, 2024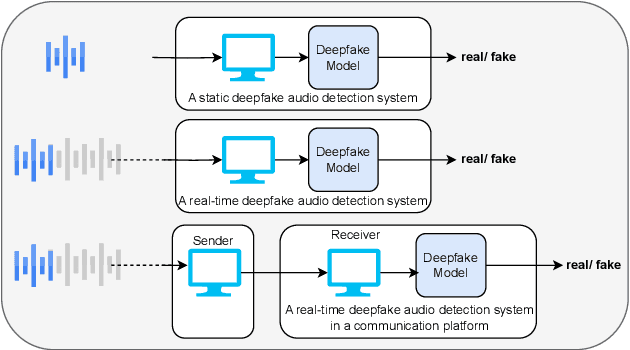
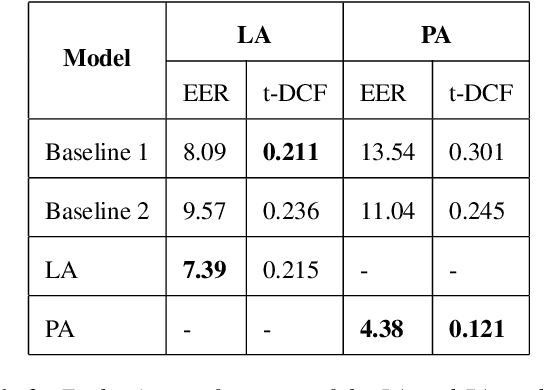
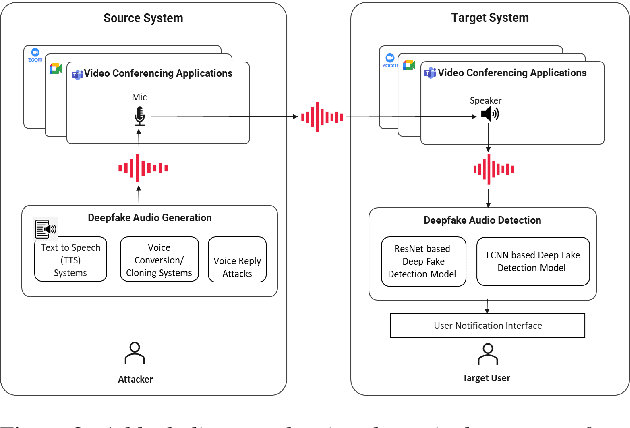
Deepfake audio poses a rising threat in communication platforms, necessitating real-time detection for audio stream integrity. Unlike traditional non-real-time approaches, this study assesses the viability of employing static deepfake audio detection models in real-time communication platforms. An executable software is developed for cross-platform compatibility, enabling real-time execution. Two deepfake audio detection models based on Resnet and LCNN architectures are implemented using the ASVspoof 2019 dataset, achieving benchmark performances compared to ASVspoof 2019 challenge baselines. The study proposes strategies and frameworks for enhancing these models, paving the way for real-time deepfake audio detection in communication platforms. This work contributes to the advancement of audio stream security, ensuring robust detection capabilities in dynamic, real-time communication scenarios.