 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Development of a Real-Time Deepfake Audio Detection System in Communication Platforms
Paper and Code
Mar 18, 2024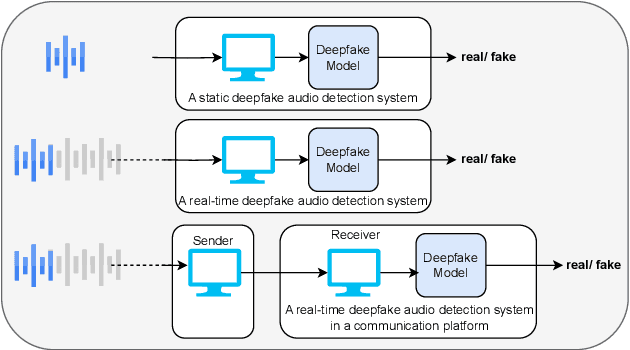
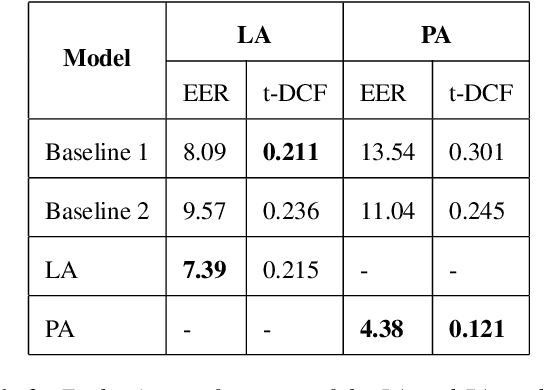
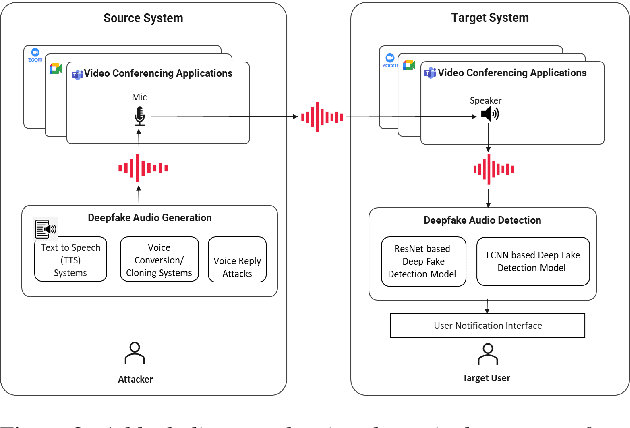
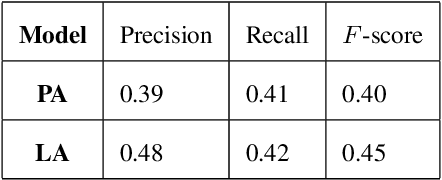
Deepfake audio poses a rising threat in communication platforms, necessitating real-time detection for audio stream integrity. Unlike traditional non-real-time approaches, this study assesses the viability of employing static deepfake audio detection models in real-time communication platforms. An executable software is developed for cross-platform compatibility, enabling real-time execution. Two deepfake audio detection models based on Resnet and LCNN architectures are implemented using the ASVspoof 2019 dataset, achieving benchmark performances compared to ASVspoof 2019 challenge baselines. The study proposes strategies and frameworks for enhancing these models, paving the way for real-time deepfake audio detection in communication platforms. This work contributes to the advancement of audio stream security, ensuring robust detection capabilities in dynamic, real-time communication scenarios.