 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive-Based Deep Embeddings for Label Noise-Resilient Histopathology Image Classification
Apr 11, 2024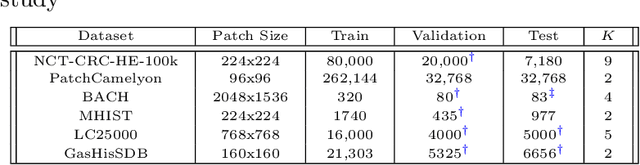
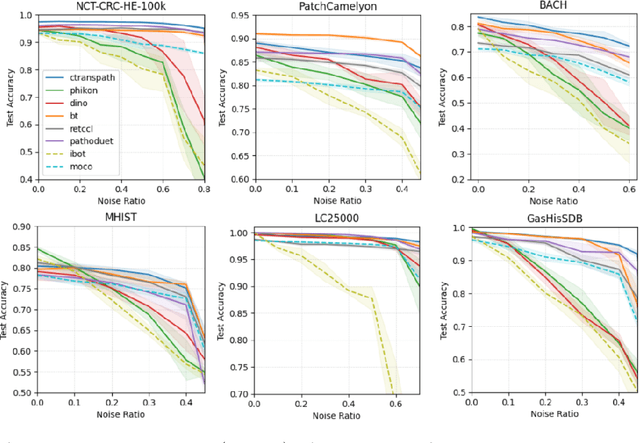
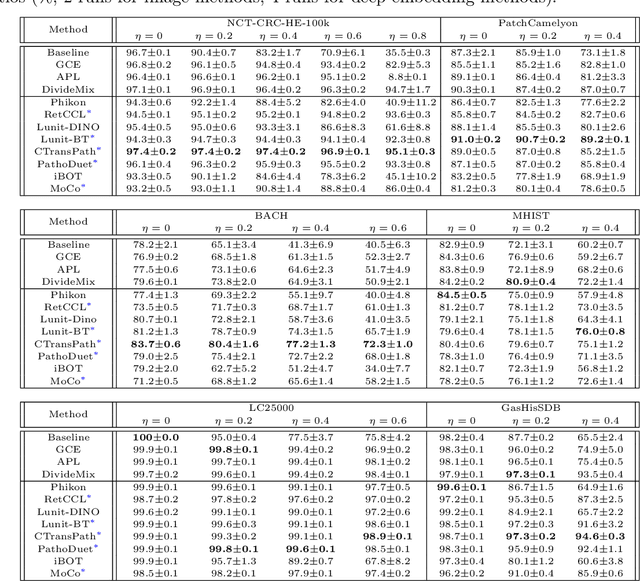
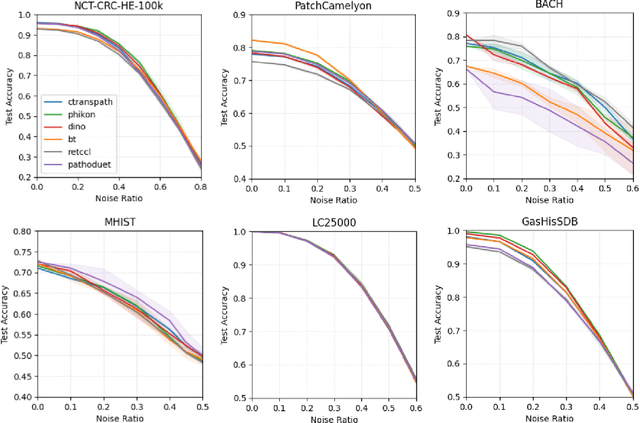
Recent advancements in deep learning have proven highly effective in medical image classification, notably within histopathology. However, noisy labels represent a critical challenge in histopathology image classification, where accurate annotations are vital for training robust deep learning models. Indeed, deep neural networks can easily overfit label noise, leading to severe degradations in model performance. While numerous public pathology foundation models have emerged recently, none have evaluated their resilience to label noise. Through thorough empirical analyses across multiple datasets, we exhibit the label noise resilience property of embeddings extracted from foundation models trained in a self-supervised contrastive manner. We demonstrate that training with such embeddings substantially enhances label noise robustness when compared to non-contrastive-based ones as well as commonly used noise-resilient methods. Our results unequivocally underline the superiority of contrastive learning in effectively mitigating the label noise challenge. Code is publicly available at https://github.com/LucasDedieu/NoiseResilientHistopathology.
Classification in Histopathology: A unique deep embeddings extractor for multiple classification tasks
Mar 09, 2023



In biomedical imaging, deep learning-based methods are state-of-the-art for every modality (virtual slides, MRI, etc.) In histopathology, these methods can be used to detect certain biomarkers or classify lesions. However, such techniques require large amounts of data to train high-performing models which can be intrinsically difficult to acquire, especially when it comes to scarce biomarkers. To address this challenge, we use a single, pre-trained, deep embeddings extractor to convert images into deep features and train small, dedicated classification head on these embeddings for each classification task. This approach offers several benefits such as the ability to reuse a single pre-trained deep network for various tasks; reducing the amount of labeled data needed as classification heads have fewer parameters; and accelerating training time by up to 1000 times, which allows for much more tuning of the classification head. In this work, we perform an extensive comparison of various open-source backbones and assess their fit to the target histological image domain. This is achieved using a novel method based on a proxy classification task. We demonstrate that thanks to this selection method, an optimal feature extractor can be selected for different tasks on the target domain. We also introduce a feature space augmentation strategy which proves to substantially improve the final metrics computed for the different tasks considered. To demonstrate the benefit of such backbone selection and feature-space augmentation, our experiments are carried out on three separate classification tasks and show a clear improvement on each of them: microcalcifications (29.1% F1-score increase), lymph nodes metastasis (12.5% F1-score increase), mitosis (15.0% F1-score increase).
Image search using multilingual texts: a cross-modal learning approach between image and text
May 14, 2019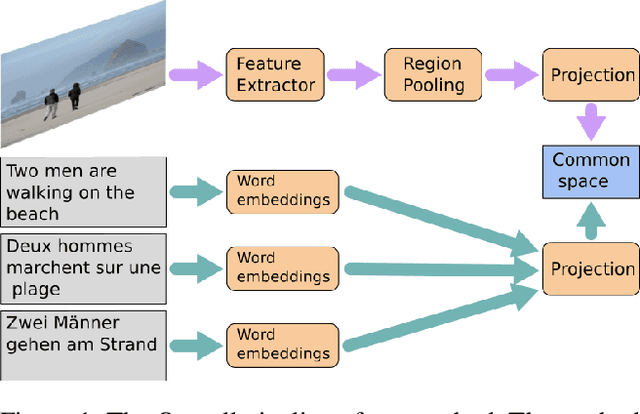
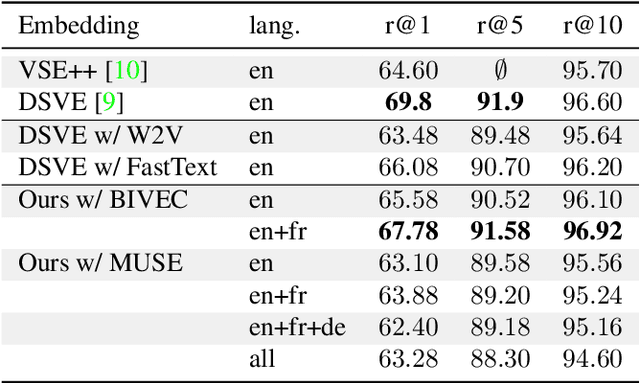
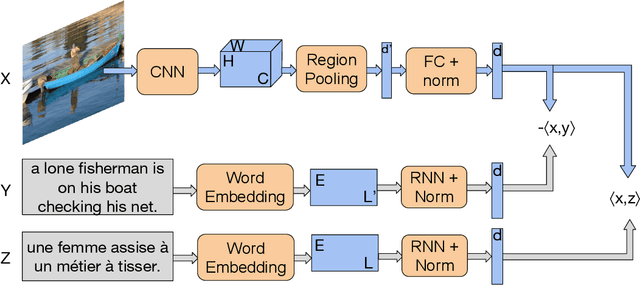
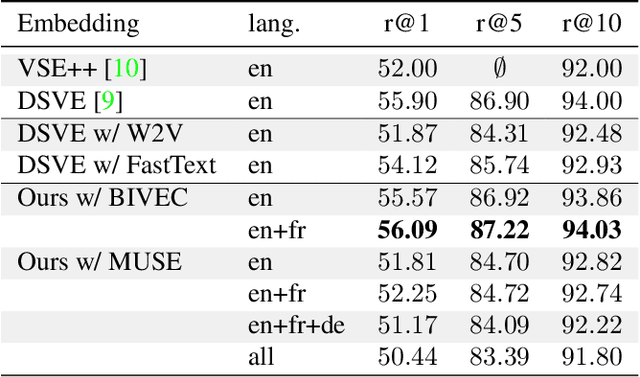
Multilingual (or cross-lingual) embeddings represent several languages in a unique vector space. Using a common embedding space enables for a shared semantic between words from different languages. In this paper, we propose to embed images and texts into a unique distributional vector space, enabling to search images by using text queries expressing information needs related to the (visual) content of images, as well as using image similarity. Our framework forces the representation of an image to be similar to the representation of the text that describes it. Moreover, by using multilingual embeddings we ensure that words from two different languages have close descriptors and thus are attached to similar images. We provide experimental evidence of the efficiency of our approach by experimenting it on two datasets: Common Objects in COntext (COCO) [19] and Multi30K [7].
Weakly Supervised Semantic Segmentation of Satellite Images
Apr 08, 2019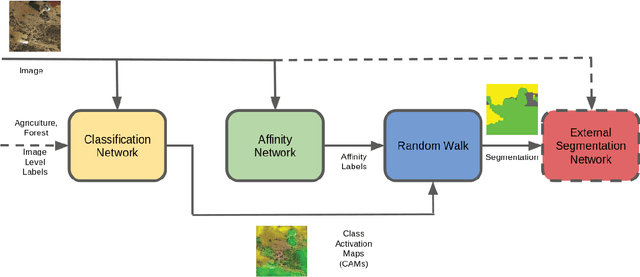
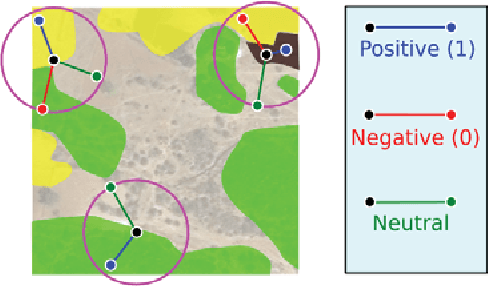
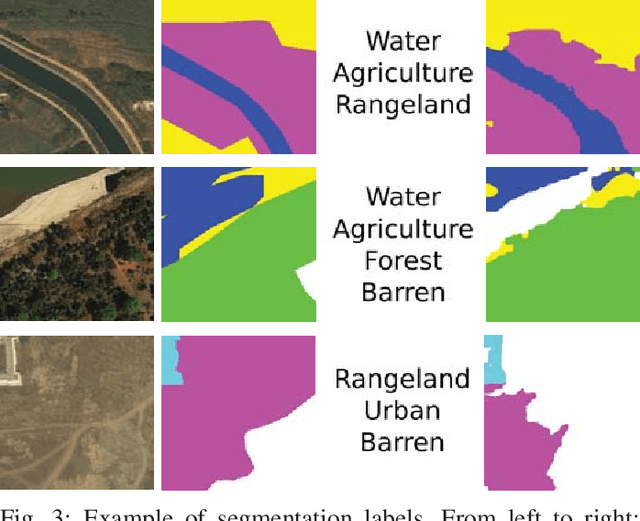
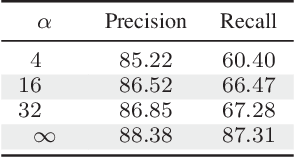
When one wants to train a neural network to perform semantic segmentation, creating pixel-level annotations for each of the images in the database is a tedious task. If he works with aerial or satellite images, which are usually very large, it is even worse. With that in mind, we investigate how to use image-level annotations in order to perform semantic segmentation. Image-level annotations are much less expensive to acquire than pixel-level annotations, but we lose a lot of information for the training of the model. From the annotations of the images, the model must find by itself how to classify the different regions of the image. In this work, we use the method proposed by Anh and Kwak [1] to produce pixel-level annotation from image level annotation. We compare the overall quality of our generated dataset with the original dataset. In addition, we propose an adaptation of the AffinityNet that allows us to directly perform a semantic segmentation. Our results show that the generated labels lead to the same performances for the training of several segmentation networks. Also, the quality of semantic segmentation performed directly by the AffinityNet and the Random Walk is close to the one of the best fully-supervised approaches.