 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Image Context Extraction with Graph Neural Networks and Sentence Embeddings on the DOM tree
Aug 26, 2021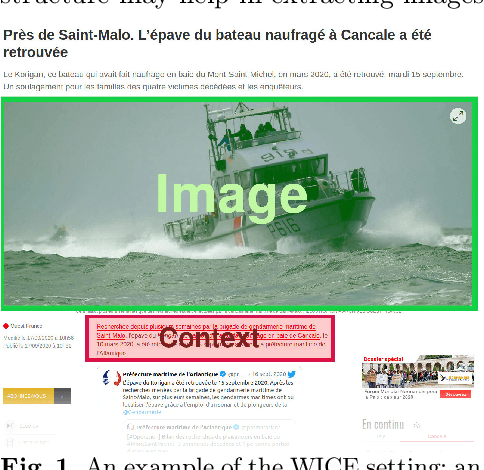
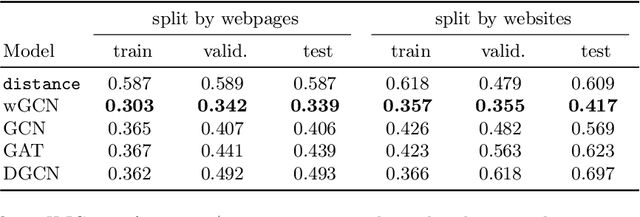
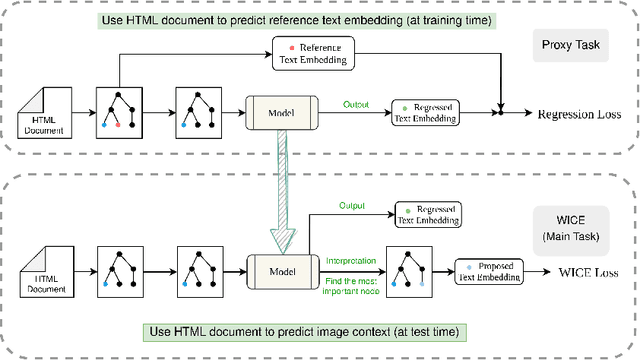
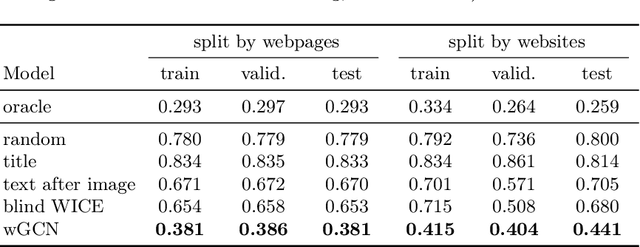
Web Image Context Extraction (WICE) consists in obtaining the textual information describing an image using the content of the surrounding webpage. A common preprocessing step before performing WICE is to render the content of the webpage. When done at a large scale (e.g., for search engine indexation), it may become very computationally costly (up to several seconds per page). To avoid this cost, we introduce a novel WICE approach that combines Graph Neural Networks (GNNs) and Natural Language Processing models. Our method relies on a graph model containing both node types and text as features. The model is fed through several blocks of GNNs to extract the textual context. Since no labeled WICE dataset with ground truth exists, we train and evaluate the GNNs on a proxy task that consists in finding the semantically closest text to the image caption. We then interpret importance weights to find the most relevant text nodes and define them as the image context. Thanks to GNNs, our model is able to encode both structural and semantic information from the webpage. We show that our approach gives promising results to help address the large-scale WICE problem using only HTML data.
Graphcore C2 Card performance for image-based deep learning application: A Report
Feb 27, 2020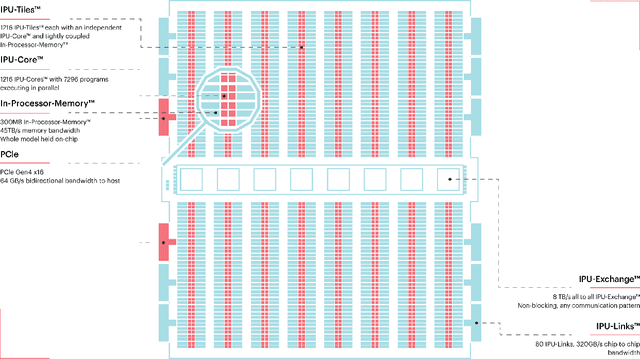
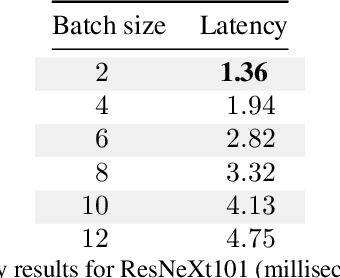
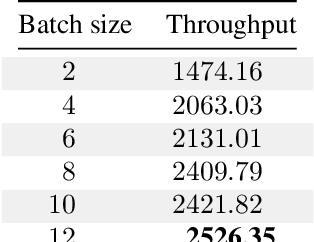
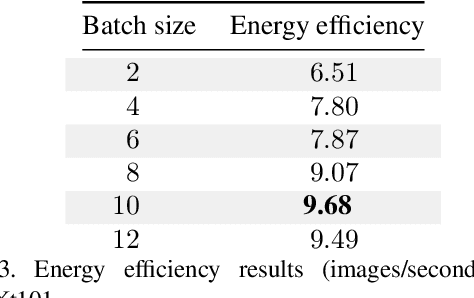
Recently, Graphcore has introduced an IPU Processor for accelerating machine learning applications. The architecture of the processor has been designed to achieve state of the art performance on current machine intelligence models for both training and inference. In this paper, we report on a benchmark in which we have evaluated the performance of IPU processors on deep neural networks for inference. We focus on deep vision models such as ResNeXt. We report the observed latency, throughput and energy efficiency.
Image search using multilingual texts: a cross-modal learning approach between image and text
May 14, 2019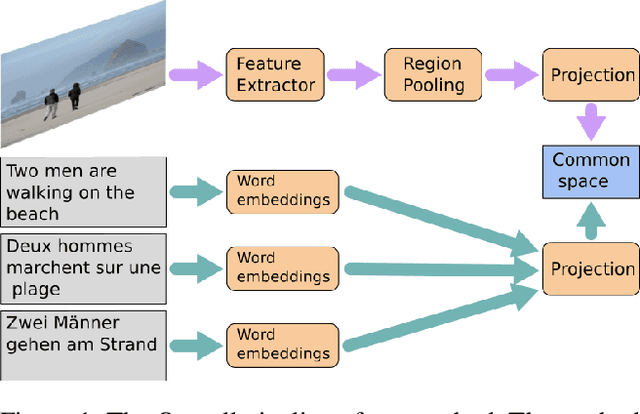
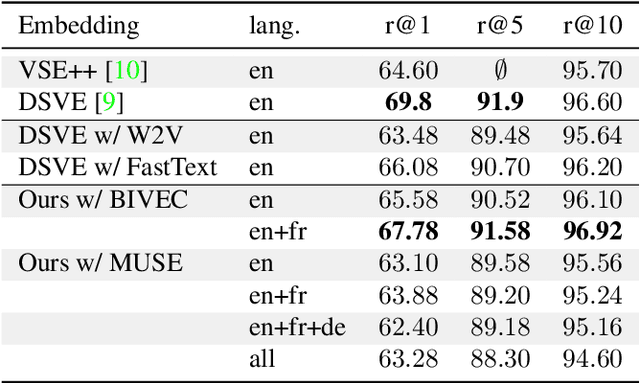
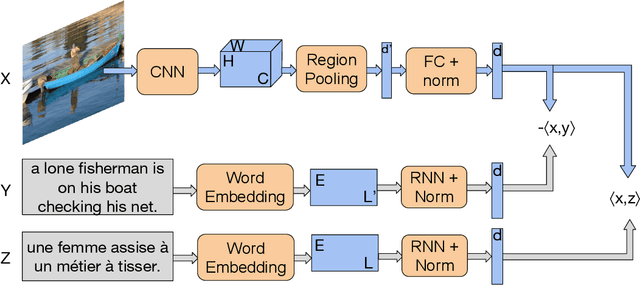
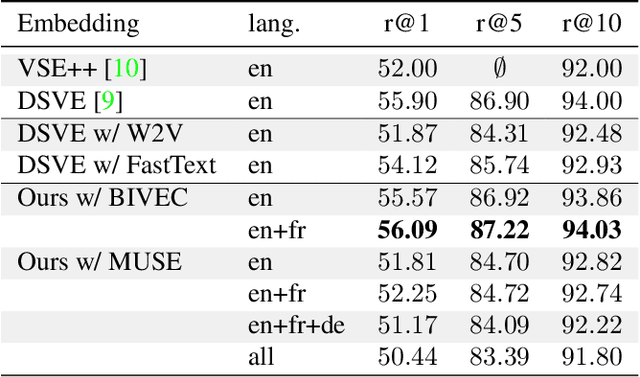
Multilingual (or cross-lingual) embeddings represent several languages in a unique vector space. Using a common embedding space enables for a shared semantic between words from different languages. In this paper, we propose to embed images and texts into a unique distributional vector space, enabling to search images by using text queries expressing information needs related to the (visual) content of images, as well as using image similarity. Our framework forces the representation of an image to be similar to the representation of the text that describes it. Moreover, by using multilingual embeddings we ensure that words from two different languages have close descriptors and thus are attached to similar images. We provide experimental evidence of the efficiency of our approach by experimenting it on two datasets: Common Objects in COntext (COCO) [19] and Multi30K [7].
Weakly Supervised Semantic Segmentation of Satellite Images
Apr 08, 2019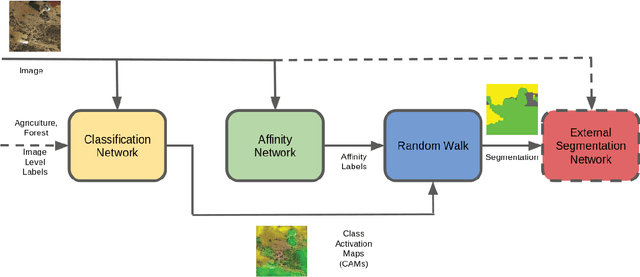
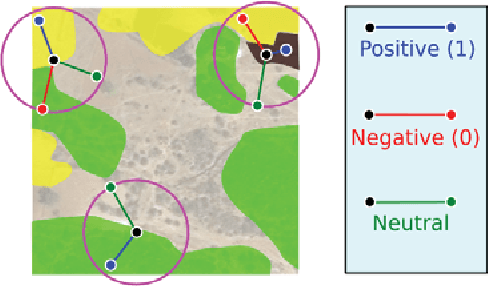
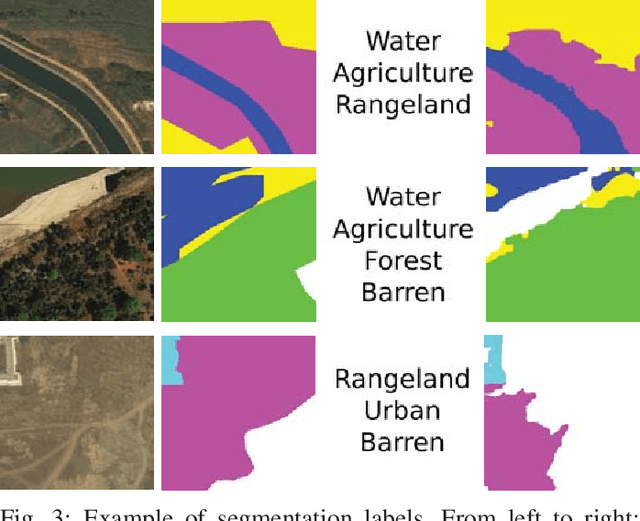
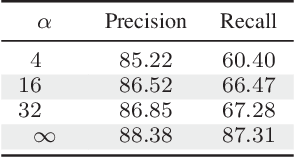
When one wants to train a neural network to perform semantic segmentation, creating pixel-level annotations for each of the images in the database is a tedious task. If he works with aerial or satellite images, which are usually very large, it is even worse. With that in mind, we investigate how to use image-level annotations in order to perform semantic segmentation. Image-level annotations are much less expensive to acquire than pixel-level annotations, but we lose a lot of information for the training of the model. From the annotations of the images, the model must find by itself how to classify the different regions of the image. In this work, we use the method proposed by Anh and Kwak [1] to produce pixel-level annotation from image level annotation. We compare the overall quality of our generated dataset with the original dataset. In addition, we propose an adaptation of the AffinityNet that allows us to directly perform a semantic segmentation. Our results show that the generated labels lead to the same performances for the training of several segmentation networks. Also, the quality of semantic segmentation performed directly by the AffinityNet and the Random Walk is close to the one of the best fully-supervised approaches.