 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Semantic Segmentation of Satellite Images
Paper and Code
Apr 08, 2019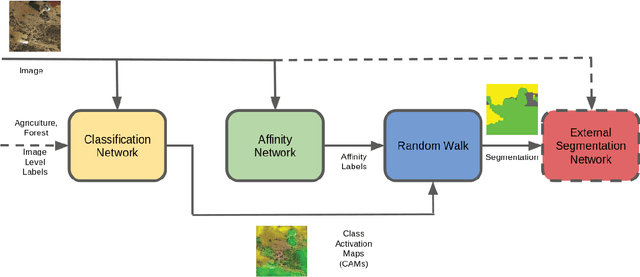
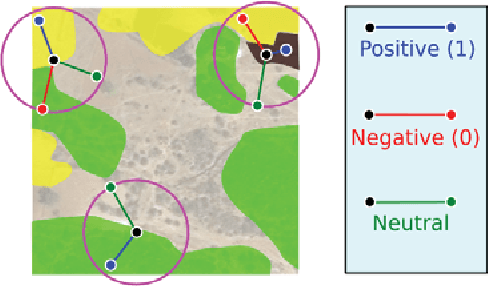
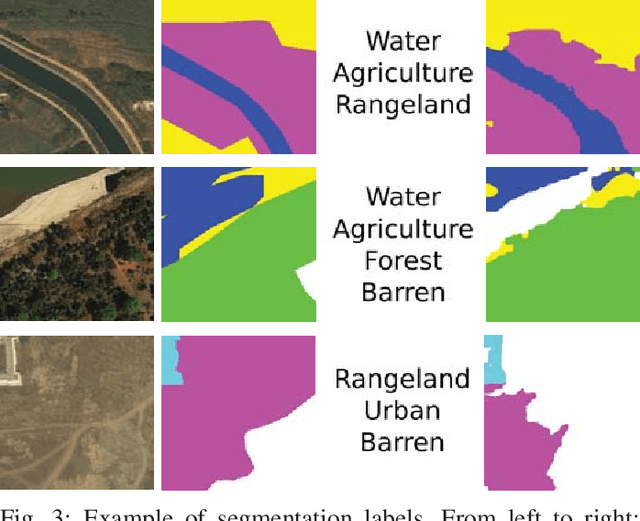
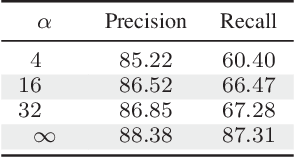
When one wants to train a neural network to perform semantic segmentation, creating pixel-level annotations for each of the images in the database is a tedious task. If he works with aerial or satellite images, which are usually very large, it is even worse. With that in mind, we investigate how to use image-level annotations in order to perform semantic segmentation. Image-level annotations are much less expensive to acquire than pixel-level annotations, but we lose a lot of information for the training of the model. From the annotations of the images, the model must find by itself how to classify the different regions of the image. In this work, we use the method proposed by Anh and Kwak [1] to produce pixel-level annotation from image level annotation. We compare the overall quality of our generated dataset with the original dataset. In addition, we propose an adaptation of the AffinityNet that allows us to directly perform a semantic segmentation. Our results show that the generated labels lead to the same performances for the training of several segmentation networks. Also, the quality of semantic segmentation performed directly by the AffinityNet and the Random Walk is close to the one of the best fully-supervised approaches.