 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive-Based Deep Embeddings for Label Noise-Resilient Histopathology Image Classification
Apr 11, 2024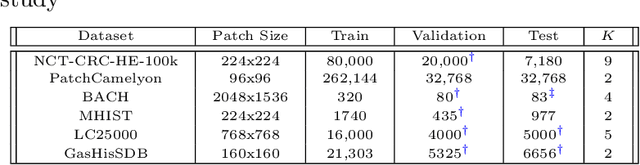
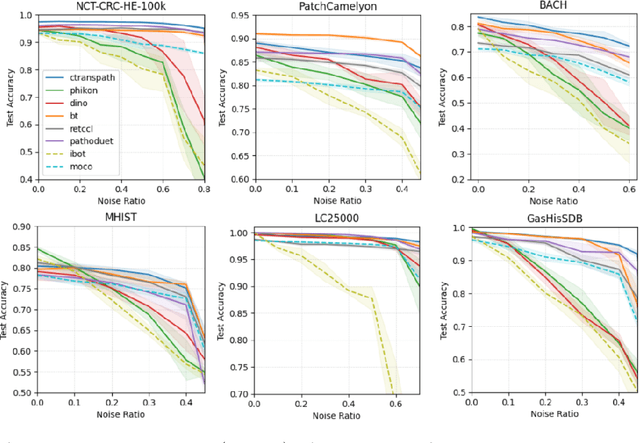
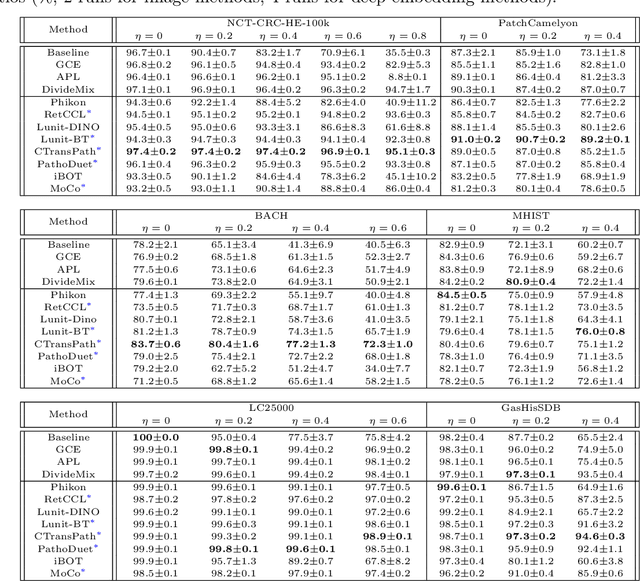
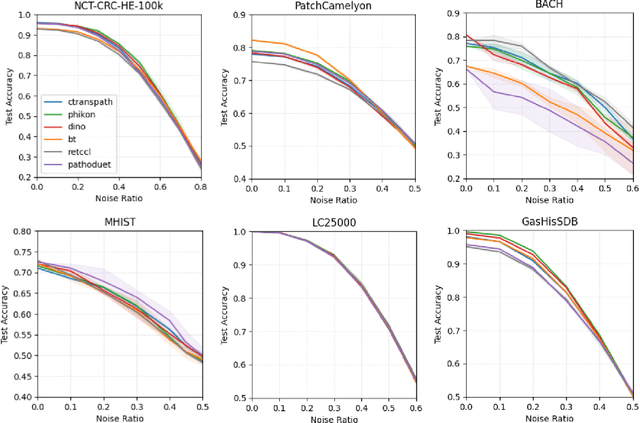
Recent advancements in deep learning have proven highly effective in medical image classification, notably within histopathology. However, noisy labels represent a critical challenge in histopathology image classification, where accurate annotations are vital for training robust deep learning models. Indeed, deep neural networks can easily overfit label noise, leading to severe degradations in model performance. While numerous public pathology foundation models have emerged recently, none have evaluated their resilience to label noise. Through thorough empirical analyses across multiple datasets, we exhibit the label noise resilience property of embeddings extracted from foundation models trained in a self-supervised contrastive manner. We demonstrate that training with such embeddings substantially enhances label noise robustness when compared to non-contrastive-based ones as well as commonly used noise-resilient methods. Our results unequivocally underline the superiority of contrastive learning in effectively mitigating the label noise challenge. Code is publicly available at https://github.com/LucasDedieu/NoiseResilientHistopathology.
Classification in Histopathology: A unique deep embeddings extractor for multiple classification tasks
Mar 09, 2023



In biomedical imaging, deep learning-based methods are state-of-the-art for every modality (virtual slides, MRI, etc.) In histopathology, these methods can be used to detect certain biomarkers or classify lesions. However, such techniques require large amounts of data to train high-performing models which can be intrinsically difficult to acquire, especially when it comes to scarce biomarkers. To address this challenge, we use a single, pre-trained, deep embeddings extractor to convert images into deep features and train small, dedicated classification head on these embeddings for each classification task. This approach offers several benefits such as the ability to reuse a single pre-trained deep network for various tasks; reducing the amount of labeled data needed as classification heads have fewer parameters; and accelerating training time by up to 1000 times, which allows for much more tuning of the classification head. In this work, we perform an extensive comparison of various open-source backbones and assess their fit to the target histological image domain. This is achieved using a novel method based on a proxy classification task. We demonstrate that thanks to this selection method, an optimal feature extractor can be selected for different tasks on the target domain. We also introduce a feature space augmentation strategy which proves to substantially improve the final metrics computed for the different tasks considered. To demonstrate the benefit of such backbone selection and feature-space augmentation, our experiments are carried out on three separate classification tasks and show a clear improvement on each of them: microcalcifications (29.1% F1-score increase), lymph nodes metastasis (12.5% F1-score increase), mitosis (15.0% F1-score increase).
Standardized CycleGAN training for unsupervised stain adaptation in invasive carcinoma classification for breast histopathology
Jan 30, 2023Generalization is one of the main challenges of computational pathology. Slide preparation heterogeneity and the diversity of scanners lead to poor model performance when used on data from medical centers not seen during training. In order to achieve stain invariance in breast invasive carcinoma patch classification, we implement a stain translation strategy using cycleGANs for unsupervised image-to-image translation. We compare three cycleGAN-based approaches to a baseline classification model obtained without any stain invariance strategy. Two of the proposed approaches use cycleGAN's translations at inference or training in order to build stain-specific classification models. The last method uses them for stain data augmentation during training. This constrains the classification model to learn stain-invariant features. Baseline metrics are set by training and testing the baseline classification model on a reference stain. We assessed performances using three medical centers with H&E and H&E&S staining. Every approach tested in this study improves baseline metrics without needing labels on target stains. The stain augmentation-based approach produced the best results on every stain. Each method's pros and cons are studied and discussed in this paper. However, training highly performing cycleGANs models in itself represents a challenge. In this work, we introduce a systematical method for optimizing cycleGAN training by setting a novel stopping criterion. This method has the benefit of not requiring any visual inspection of cycleGAN results and proves superiority to methods using a predefined number of training epochs. In addition, we also study the minimal amount of data required for cycleGAN training.