 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRIMGEP: Learning Progress for Robust Goal Sampling in Visual Deep Reinforcement Learning
Aug 10, 2020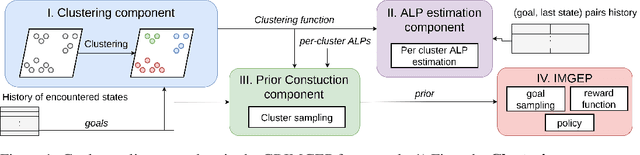


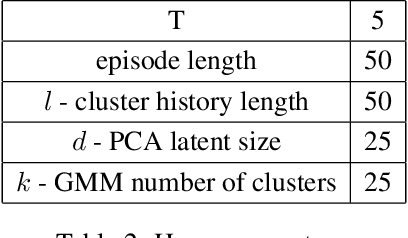
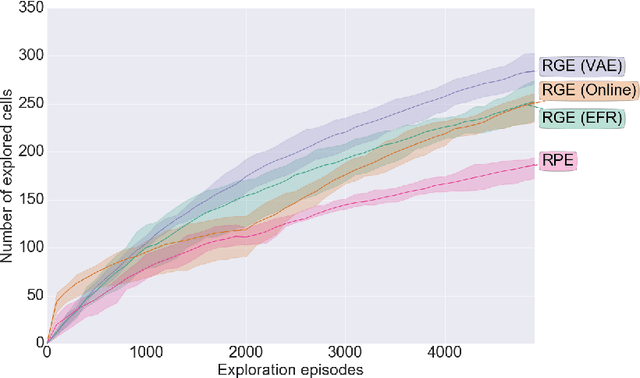
Autonomous agents using novelty based goal exploration are often efficient in environments that require exploration. However, they get attracted to various forms of distracting unlearnable regions. To solve this problem, absolute learning progress (ALP) has been used in reinforcement learning agents with predefined goal features and access to expert knowledge. This work extends those concepts to unsupervised image-based goal exploration. We present the GRIMGEP framework: it provides a learned robust goal sampling prior that can be used on top of current state-of-the-art novelty seeking goal exploration approaches, enabling them to ignore noisy distracting regions while searching for novelty in the learnable regions. It clusters the goal space and estimates ALP for each cluster. These ALP estimates can then be used to detect the distracting regions, and build a prior that enables further goal sampling mechanisms to ignore them. We construct an image based environment with distractors, on which we show that wrapping current state-of-the-art goal exploration algorithms with our framework allows them to concentrate on interesting regions of the environment and drastically improve performances. The source code is available at https://sites.google.com/view/grimgep.
Autonomous Goal Exploration using Learned Goal Spaces for Visuomotor Skill Acquisition in Robots
Jun 10, 2019

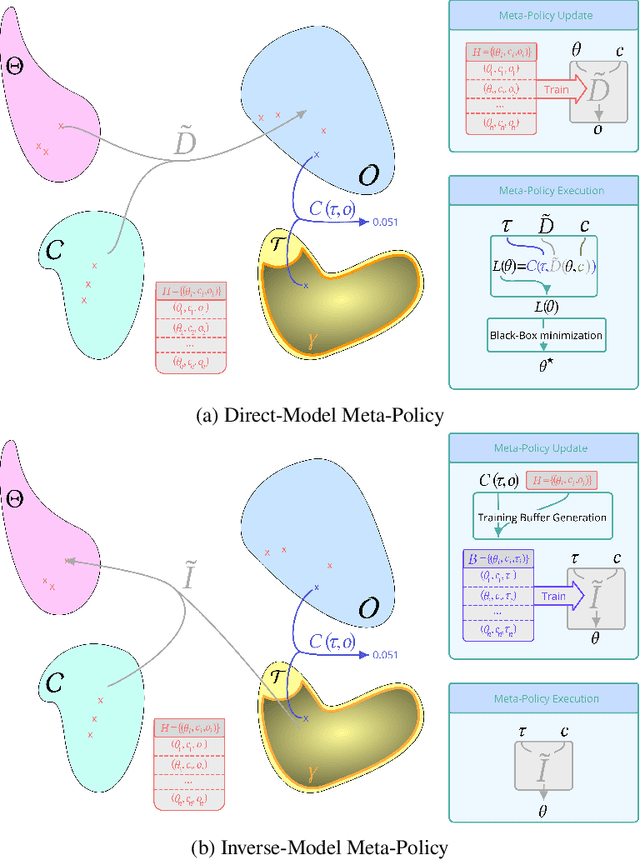
The automatic and efficient discovery of skills, without supervision, for long-living autonomous agents, remains a challenge of Artificial Intelligence. Intrinsically Motivated Goal Exploration Processes give learning agents a human-inspired mechanism to sequentially select goals to achieve. This approach gives a new perspective on the lifelong learning problem, with promising results on both simulated and real-world experiments. Until recently, those algorithms were restricted to domains with experimenter-knowledge, since the Goal Space used by the agents was built on engineered feature extractors. The recent advances of deep representation learning, enables new ways of designing those feature extractors, using directly the agent experience. Recent work has shown the potential of those methods on simple yet challenging simulated domains. In this paper, we present recent results showing the applicability of those principles on a real-world robotic setup, where a 6-joint robotic arm learns to manipulate a ball inside an arena, by choosing goals in a space learned from its past experience.
Curiosity Driven Exploration of Learned Disentangled Goal Spaces
Nov 04, 2018
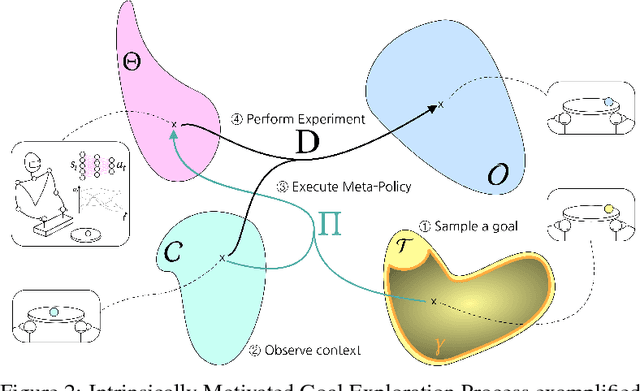
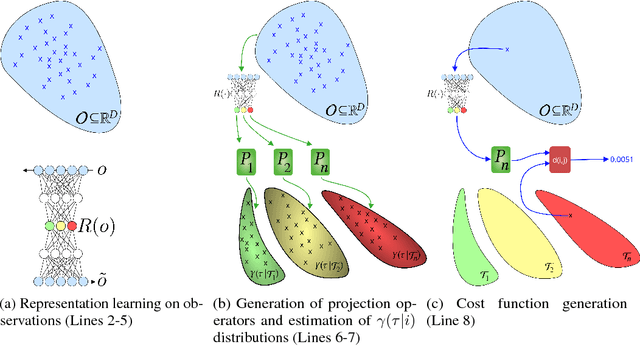

Intrinsically motivated goal exploration processes enable agents to autonomously sample goals to explore efficiently complex environments with high-dimensional continuous actions. They have been applied successfully to real world robots to discover repertoires of policies producing a wide diversity of effects. Often these algorithms relied on engineered goal spaces but it was recently shown that one can use deep representation learning algorithms to learn an adequate goal space in simple environments. However, in the case of more complex environments containing multiple objects or distractors, an efficient exploration requires that the structure of the goal space reflects the one of the environment. In this paper we show that using a disentangled goal space leads to better exploration performances than an entangled goal space. We further show that when the representation is disentangled, one can leverage it by sampling goals that maximize learning progress in a modular manner. Finally, we show that the measure of learning progress, used to drive curiosity-driven exploration, can be used simultaneously to discover abstract independently controllable features of the environment.
* The code used in the experiments is available at https://github.com/flowersteam/Curiosity_Driven_Goal_Exploration