 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuriosity Driven Exploration of Learned Disentangled Goal Spaces
Paper and Code

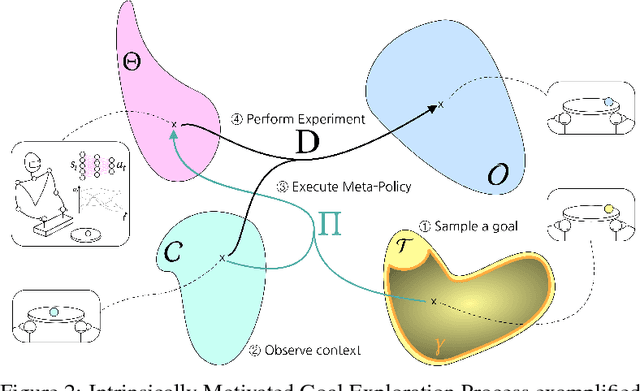
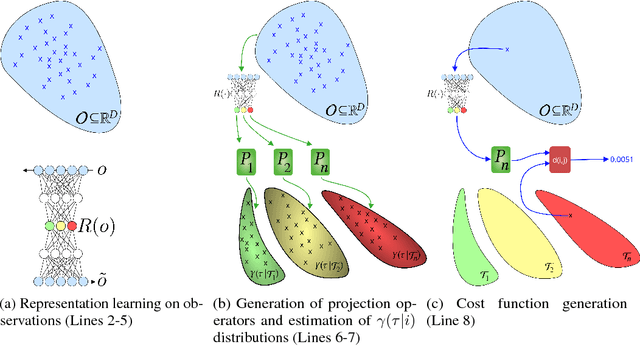

Intrinsically motivated goal exploration processes enable agents to autonomously sample goals to explore efficiently complex environments with high-dimensional continuous actions. They have been applied successfully to real world robots to discover repertoires of policies producing a wide diversity of effects. Often these algorithms relied on engineered goal spaces but it was recently shown that one can use deep representation learning algorithms to learn an adequate goal space in simple environments. However, in the case of more complex environments containing multiple objects or distractors, an efficient exploration requires that the structure of the goal space reflects the one of the environment. In this paper we show that using a disentangled goal space leads to better exploration performances than an entangled goal space. We further show that when the representation is disentangled, one can leverage it by sampling goals that maximize learning progress in a modular manner. Finally, we show that the measure of learning progress, used to drive curiosity-driven exploration, can be used simultaneously to discover abstract independently controllable features of the environment.