 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Preselection with Context Information under the Plackett-Luce Model
Feb 11, 2020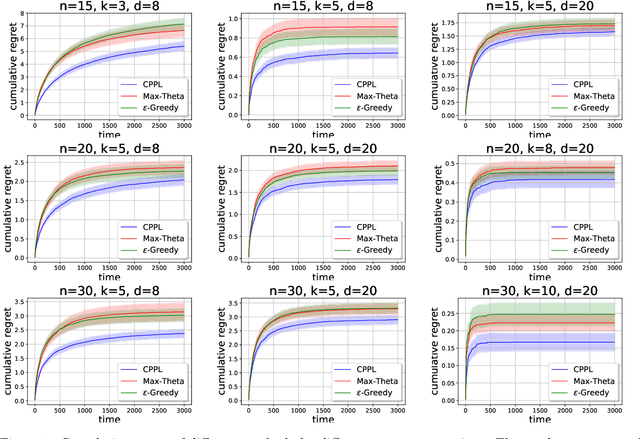
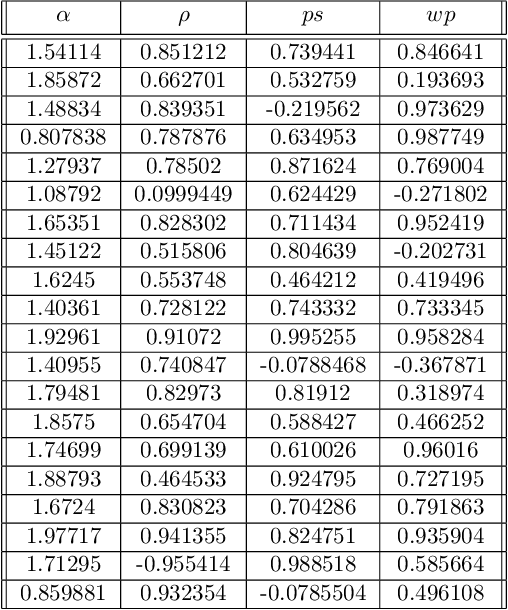
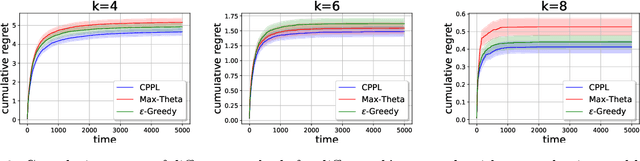
We consider an extension of the contextual multi-armed bandit problem, in which, instead of selecting a single alternative (arm), a learner is supposed to make a preselection in the form of a subset of alternatives. More specifically, in each iteration, the learner is presented a set of arms and a context, both described in terms of feature vectors. The task of the learner is to preselect $k$ of these arms, among which a final choice is made in a second step. In our setup, we assume that each arm has a latent (context-dependent) utility, and that feedback on a preselection is produced according to a Plackett-Luce model. We propose the CPPL algorithm, which is inspired by the well-known UCB algorithm, and evaluate this algorithm on synthetic and real data. In particular, we consider an online algorithm selection scenario, which served as a main motivation of our problem setting. Here, an instance (which defines the context) from a certain problem class (such as SAT) can be solved by different algorithms (the arms), but only $k$ of these algorithms can actually be run.
Preference-based Online Learning with Dueling Bandits: A Survey
Jul 30, 2018
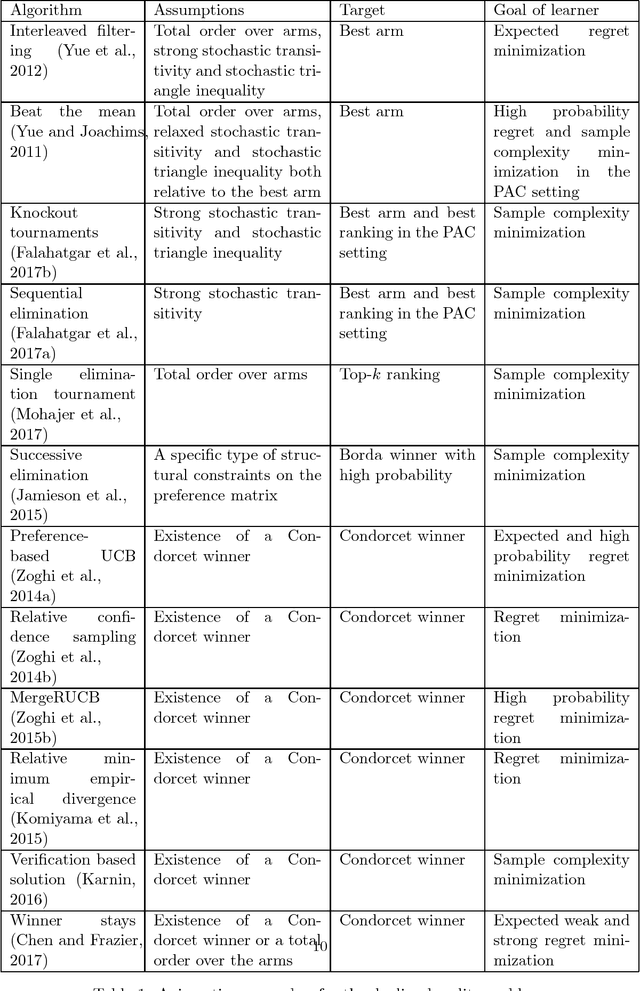
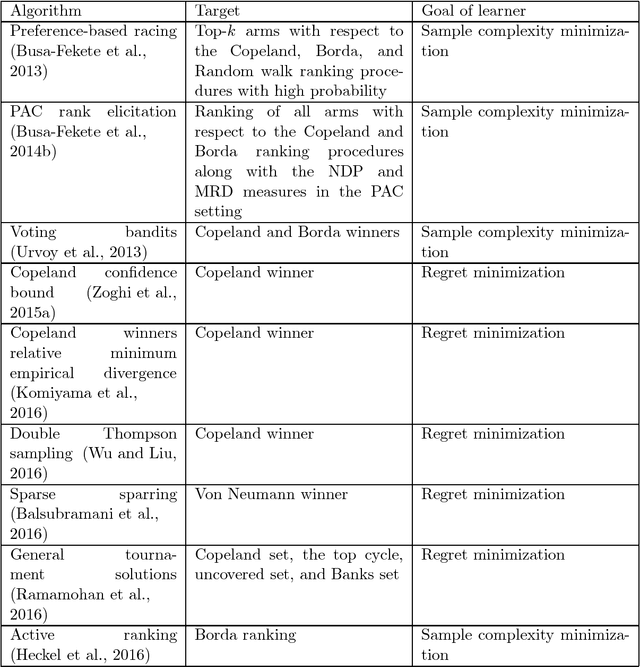
In machine learning, the notion of multi-armed bandits refers to a class of online learning problems, in which an agent is supposed to simultaneously explore and exploit a given set of choice alternatives in the course of a sequential decision process. In the standard setting, the agent learns from stochastic feedback in the form of real-valued rewards. In many applications, however, numerical reward signals are not readily available -- instead, only weaker information is provided, in particular relative preferences in the form of qualitative comparisons between pairs of alternatives. This observation has motivated the study of variants of the multi-armed bandit problem, in which more general representations are used both for the type of feedback to learn from and the target of prediction. The aim of this paper is to provide a survey of the state of the art in this field, referred to as preference-based multi-armed bandits or dueling bandits. To this end, we provide an overview of problems that have been considered in the literature as well as methods for tackling them. Our taxonomy is mainly based on the assumptions made by these methods about the data-generating process and, related to this, the properties of the preference-based feedback.