 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipal component analysis balancing prediction and approximation accuracy for spatial data
Aug 03, 2024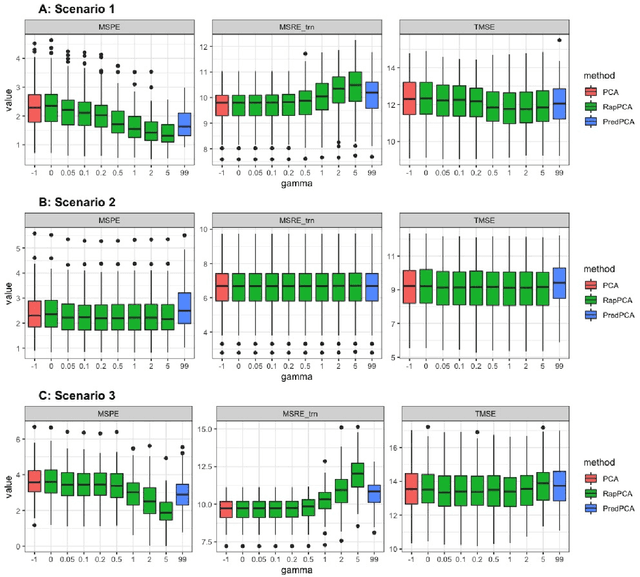


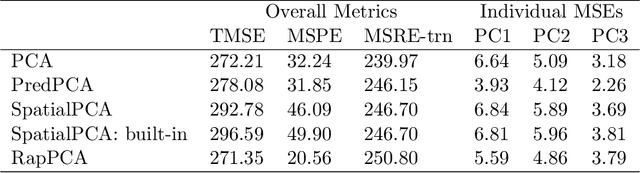
Dimension reduction is often the first step in statistical modeling or prediction of multivariate spatial data. However, most existing dimension reduction techniques do not account for the spatial correlation between observations and do not take the downstream modeling task into consideration when finding the lower-dimensional representation. We formalize the closeness of approximation to the original data and the utility of lower-dimensional scores for downstream modeling as two complementary, sometimes conflicting, metrics for dimension reduction. We illustrate how existing methodologies fall into this framework and propose a flexible dimension reduction algorithm that achieves the optimal trade-off. We derive a computationally simple form for our algorithm and illustrate its performance through simulation studies, as well as two applications in air pollution modeling and spatial transcriptomics.
Variable importance measure for spatial machine learning models with application to air pollution exposure prediction
Jun 04, 2024



Exposure assessment is fundamental to air pollution cohort studies. The objective is to predict air pollution exposures for study subjects at locations without data in order to optimize our ability to learn about health effects of air pollution. In addition to generating accurate predictions to minimize exposure measurement error, understanding the mechanism captured by the model is another crucial aspect that may not always be straightforward due to the complex nature of machine learning methods, as well as the lack of unifying notions of variable importance. This is further complicated in air pollution modeling by the presence of spatial correlation. We tackle these challenges in two datasets: sulfur (S) from regulatory United States national PM2.5 sub-species data and ultrafine particles (UFP) from a new Seattle-area traffic-related air pollution dataset. Our key contribution is a leave-one-out approach for variable importance that leads to interpretable and comparable measures for a broad class of models with separable mean and covariance components. We illustrate our approach with several spatial machine learning models, and it clearly highlights the difference in model mechanisms, even for those producing similar predictions. We leverage insights from this variable importance measure to assess the relative utilities of two exposure models for S and UFP that have similar out-of-sample prediction accuracies but appear to draw on different types of spatial information to make predictions.