 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Transitivity Constraints for Entity Matching in Knowledge Graphs
Apr 22, 2021


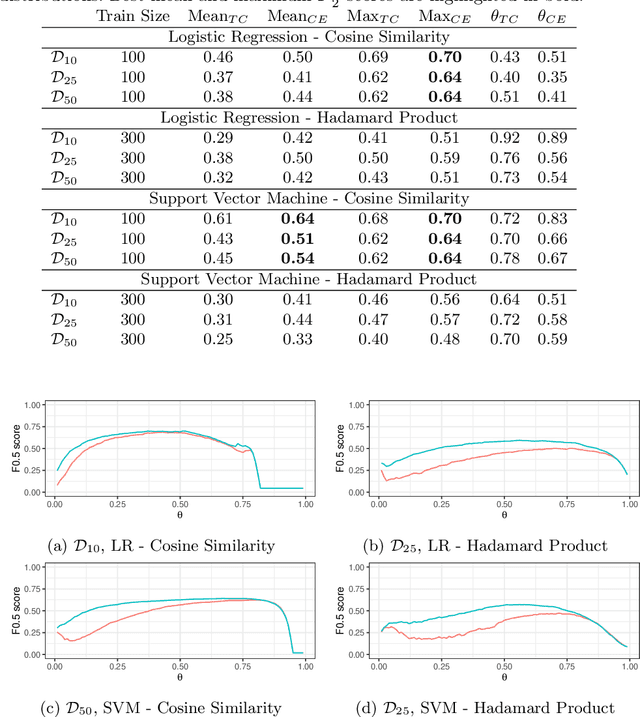
The goal of entity matching in knowledge graphs is to identify entities that refer to the same real-world objects using some similarity metric. The result of entity matching can be seen as a set of entity pairs interpreted as the same-as relation. However, the identified set of pairs may fail to satisfy some structural properties, in particular transitivity, that are expected from the same-as relation. In this work, we show that an ad-hoc enforcement of transitivity, i.e. taking the transitive closure, on the identified set of entity pairs may decrease precision dramatically. We therefore propose a methodology that starts with a given similarity measure, generates a set of entity pairs that are identified as referring to the same real-world objects, and applies the cluster editing algorithm to enforce transitivity without adding many spurious links, leading to overall improved performance.
Monotonicity in Bayesian Networks
Jul 11, 2012
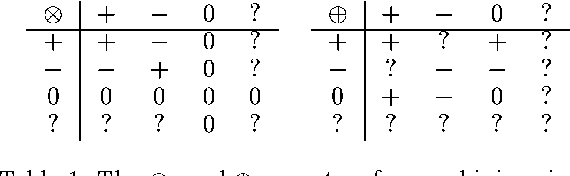
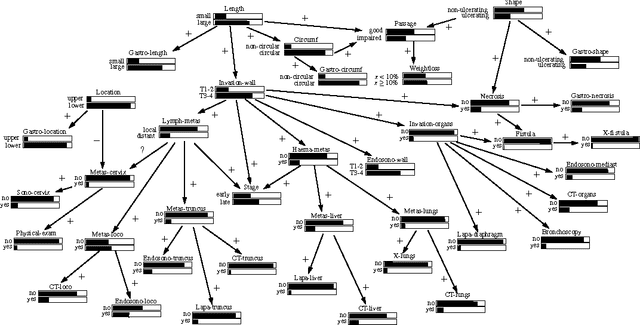
For many real-life Bayesian networks, common knowledge dictates that the output established for the main variable of interest increases with higher values for the observable variables. We define two concepts of monotonicity to capture this type of knowledge. We say that a network is isotone in distribution if the probability distribution computed for the output variable given specific observations is stochastically dominated by any such distribution given higher-ordered observations; a network is isotone in mode if a probability distribution given higher observations has a higher mode. We show that establishing whether a network exhibits any of these properties of monotonicity is coNPPP-complete in general, and remains coNP-complete for polytrees. We present an approximate algorithm for deciding whether a network is monotone in distribution and illustrate its application to a real-life network in oncology.
Learning Bayesian Network Parameters with Prior Knowledge about Context-Specific Qualitative Influences
Jul 04, 2012
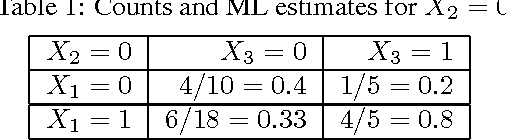


We present a method for learning the parameters of a Bayesian network with prior knowledge about the signs of influences between variables. Our method accommodates not just the standard signs, but provides for context-specific signs as well. We show how the various signs translate into order constraints on the network parameters and how isotonic regression can be used to compute order-constrained estimates from the available data. Our experimental results show that taking prior knowledge about the signs of influences into account leads to an improved fit of the true distribution, especially when only a small sample of data is available. Moreover, the computed estimates are guaranteed to be consistent with the specified signs, thereby resulting in a network that is more likely to be accepted by experts in its domain of application.
A new parameter Learning Method for Bayesian Networks with Qualitative Influences
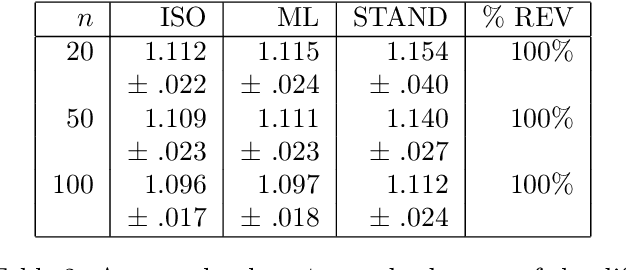
Jun 20, 2012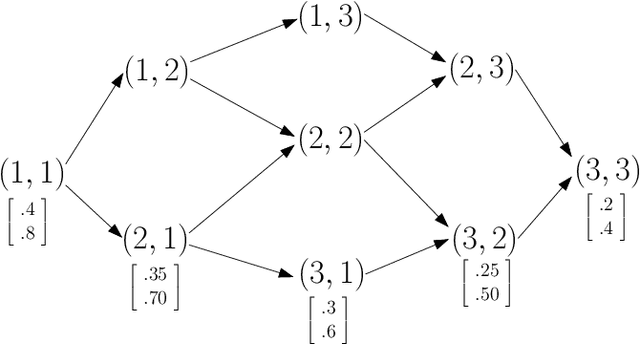


We propose a new method for parameter learning in Bayesian networks with qualitative influences. This method extends our previous work from networks of binary variables to networks of discrete variables with ordered values. The specified qualitative influences correspond to certain order restrictions on the parameters in the network. These parameters may therefore be estimated using constrained maximum likelihood estimation. We propose an alternative method, based on the isotonic regression. The constrained maximum likelihood estimates are fairly complicated to compute, whereas computation of the isotonic regression estimates only requires the repeated application of the Pool Adjacent Violators algorithm for linear orders. Therefore, the isotonic regression estimator is to be preferred from the viewpoint of computational complexity. Through experiments on simulated and real data, we show that the new learning method is competitive in performance to the constrained maximum likelihood estimator, and that both estimators improve on the standard estimator.