 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunkWise LoRA: Adaptive Sequence Partitioning for Memory-Efficient Low-Rank Adaptation and Accelerated LLM Inference
Jan 28, 2026Recent advances in low-rank adaptation (LoRA) have enabled efficient fine-tuning of large language models (LLMs) with minimal additional parameters. However, existing LoRA methods apply static rank configurations uniformly across all input tokens, ignoring variation in token complexity and computational requirements. In this work, we propose ChunkWise LoRA, a dynamic and adaptive approach that partitions sequences into variable-length chunks based on token complexity and assigns each chunk a tailored low-rank configuration. Our system introduces a runtime scheduler that estimates token difficulty, performs adaptive chunking, and selects per-chunk LoRA rank and scaling using a rank-ladder mechanism. To preserve output consistency, we further introduce a boundary-safe composition module and integrate policy-driven KV-cache strategies. Experiments on benchmark datasets such as Wikitext-103 and SQuAD demonstrate that ChunkWise LoRA achieves up to 34\% lower latency and 38% memory reduction compared to baseline LoRA, while maintaining or improving task performance metrics like BLEU, EM, and perplexity. The proposed framework remains fully compatible with existing transformer architectures and inference frameworks, providing a practical solution for real-world deployment of parameter-efficient LLMs.
Bridge type classification: supervised learning on a modified NBI dataset
Feb 12, 2018
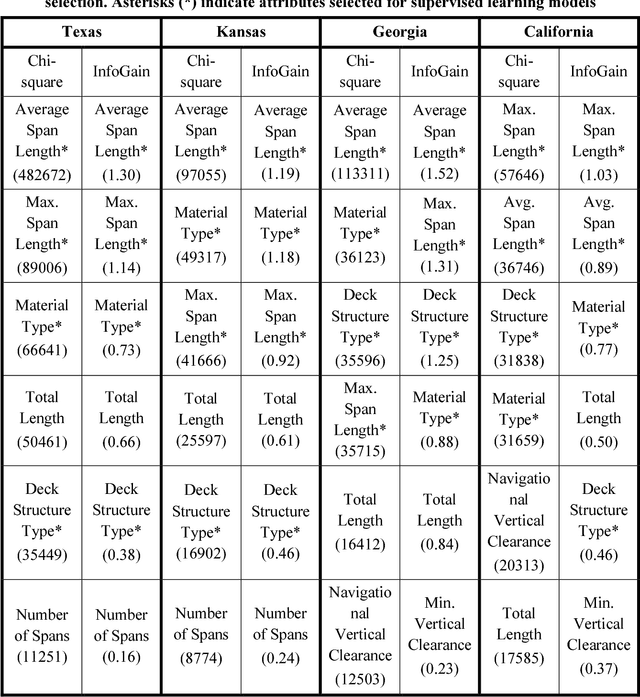
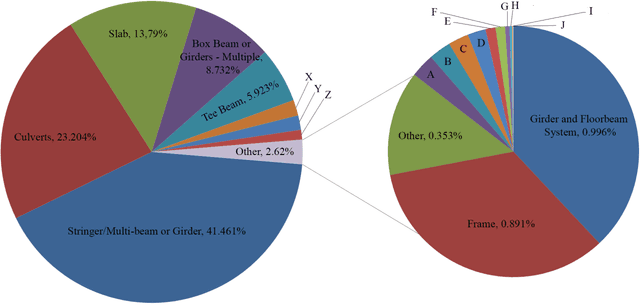
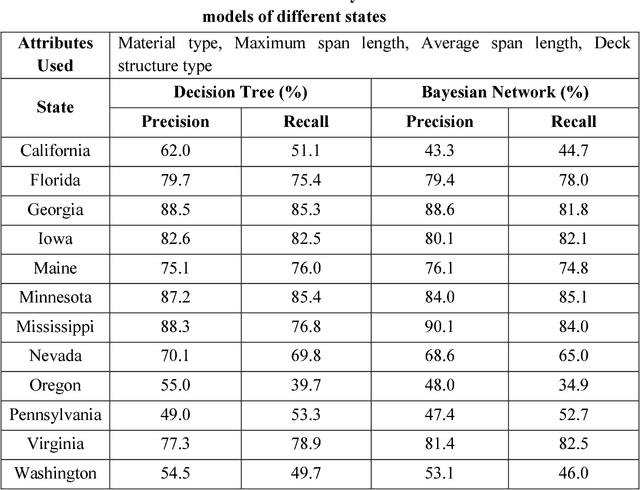
A key phase in the bridge design process is the selection of the structural system. Due to budget and time constraints, engineers typically rely on engineering judgment and prior experience when selecting a structural system, often considering a limited range of design alternatives. The objective of this study was to explore the suitability of supervised machine learning as a preliminary design aid that provides guidance to engineers with regards to the statistically optimal bridge type to choose, ultimately improving the likelihood of optimized design, design standardization, and reduced maintenance costs. In order to devise this supervised learning system, data for over 600,000 bridges from the National Bridge Inventory database were analyzed. Key attributes for determining the bridge structure type were identified through three feature selection techniques. Potentially useful attributes like seismic intensity and historic data on the cost of materials (steel and concrete) were then added from the US Geological Survey (USGS) database and Engineering News Record. Decision tree, Bayes network and Support Vector Machines were used for predicting the bridge design type. Due to state-to-state variations in material availability, material costs, and design codes, supervised learning models based on the complete data set did not yield favorable results. Supervised learning models were then trained and tested using 10-fold cross validation on data for each state. Inclusion of seismic data improved the model performance noticeably. The data was then resampled to reduce the bias of the models towards more common design types, and the supervised learning models thus constructed showed further improvements in performance. The average recall and precision for the state models was 88.6% and 88.0% using Decision Trees, 84.0% and 83.7% using Bayesian Networks, and 80.8% and 75.6% using SVM.
* Preprint of paper published in ASCE Journal of Computing (https://ascelibrary.org/doi/full/10.1061/(ASCE)CP.1943-5487.0000712). 6 figures and 8 tables, provided at end of document