 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccounting for Work Zone Disruptions in Traffic Flow Forecasting
Jul 16, 2024Traffic speed forecasting is an important task in intelligent transportation system management. The objective of much of the current computational research is to minimize the difference between predicted and actual speeds, but information modalities other than speed priors are largely not taken into account. In particular, though state of the art performance is achieved on speed forecasting with graph neural network methods, these methods do not incorporate information on roadway maintenance work zones and their impacts on predicted traffic flows; yet, the impacts of construction work zones are of significant interest to roadway management agencies, because they translate to impacts on the local economy and public well-being. In this paper, we build over the convolutional graph neural network architecture and present a novel ``Graph Convolutional Network for Roadway Work Zones" model that includes a novel data fusion mechanism and a new heterogeneous graph aggregation methodology to accommodate work zone information in spatio-temporal dependencies among traffic states. The model is evaluated on two data sets that capture traffic flows in the presence of work zones in the Commonwealth of Virginia. Extensive comparative evaluation and ablation studies show that the proposed model can capture complex and nonlinear spatio-temporal relationships across a transportation corridor, outperforming baseline models, particularly when predicting traffic flow during a workzone event.
Multiple Instance Learning for Detecting Anomalies over Sequential Real-World Datasets
Oct 04, 2022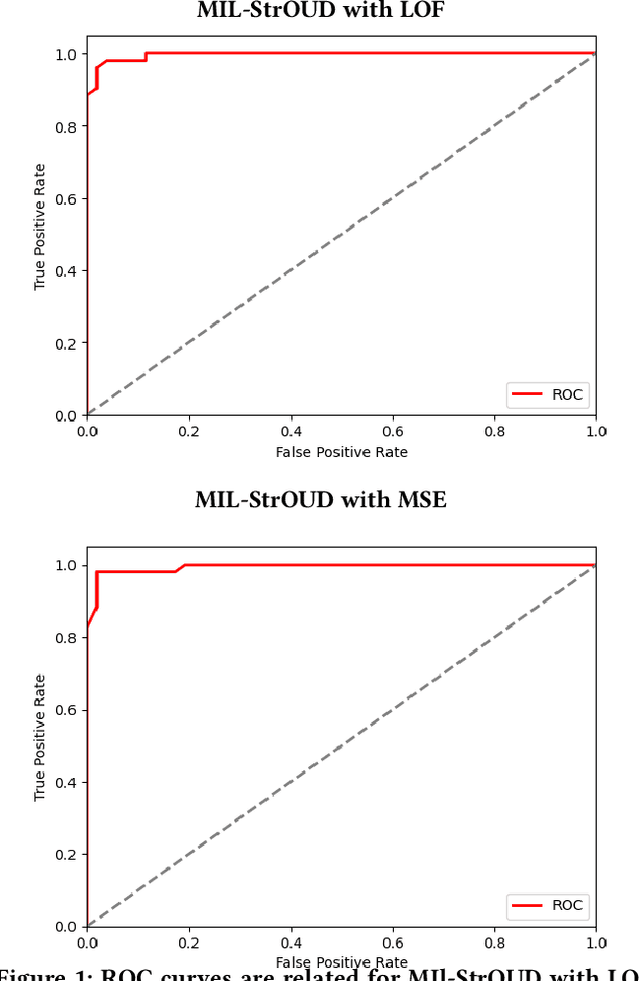
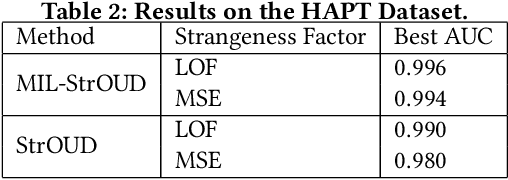
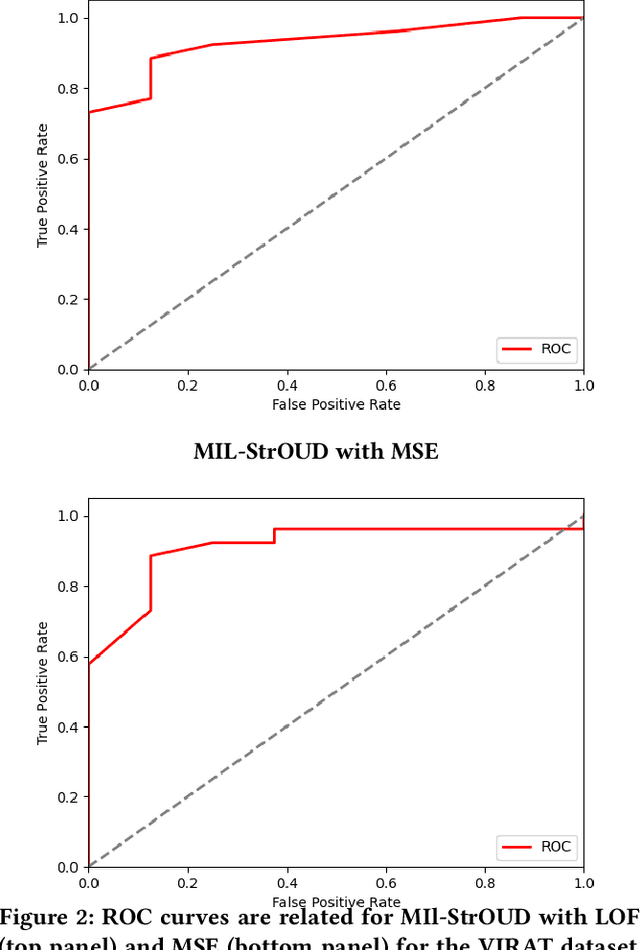
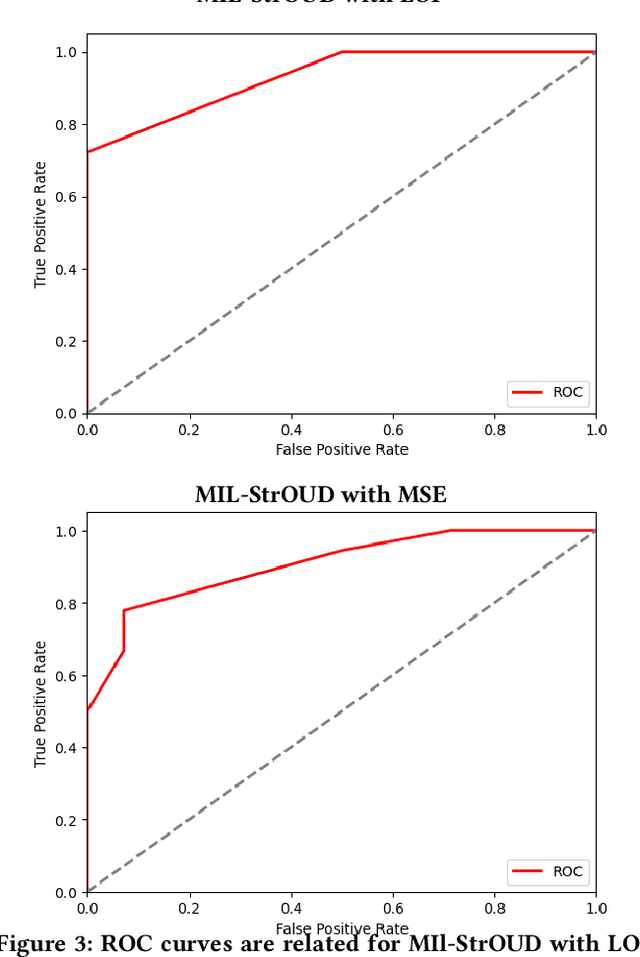
Detecting anomalies over real-world datasets remains a challenging task. Data annotation is an intensive human labor problem, particularly in sequential datasets, where the start and end time of anomalies are not known. As a result, data collected from sequential real-world processes can be largely unlabeled or contain inaccurate labels. These characteristics challenge the application of anomaly detection techniques based on supervised learning. In contrast, Multiple Instance Learning (MIL) has been shown effective on problems with incomplete knowledge of labels in the training dataset, mainly due to the notion of bags. While largely under-leveraged for anomaly detection, MIL provides an appealing formulation for anomaly detection over real-world datasets, and it is the primary contribution of this paper. In this paper, we propose an MIL-based formulation and various algorithmic instantiations of this framework based on different design decisions for key components of the framework. We evaluate the resulting algorithms over four datasets that capture different physical processes along different modalities. The experimental evaluation draws out several observations. The MIL-based formulation performs no worse than single instance learning on easy to moderate datasets and outperforms single-instance learning on more challenging datasets. Altogether, the results show that the framework generalizes well over diverse datasets resulting from different real-world application domains.
Traffic Flow Forecasting with Maintenance Downtime via Multi-Channel Attention-Based Spatio-Temporal Graph Convolutional Networks
Oct 04, 2021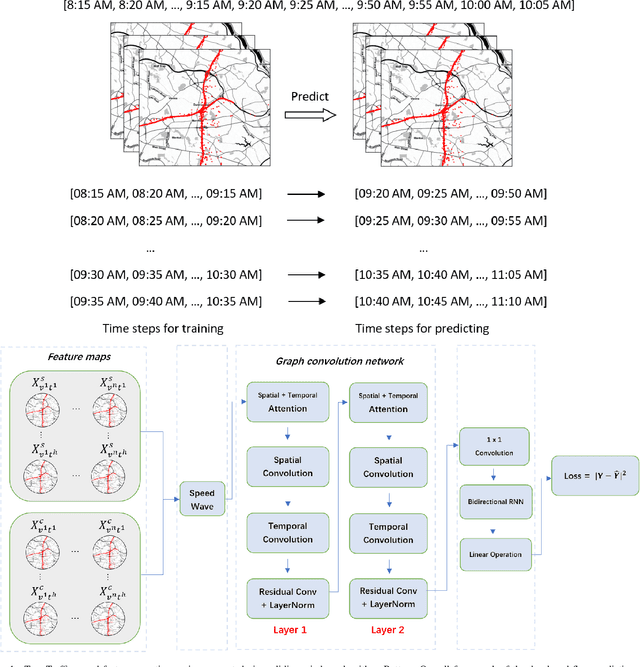
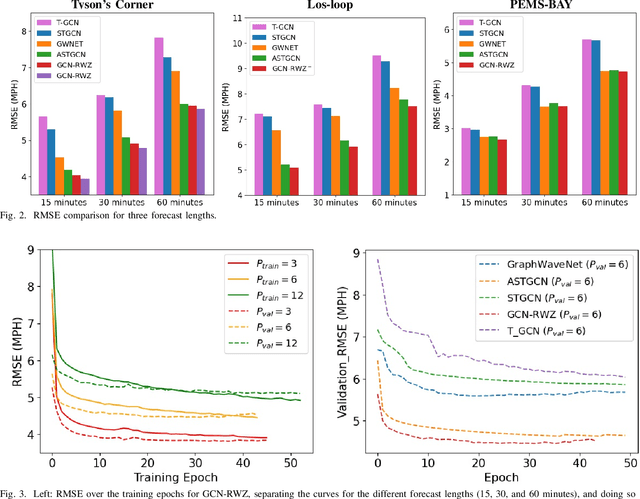
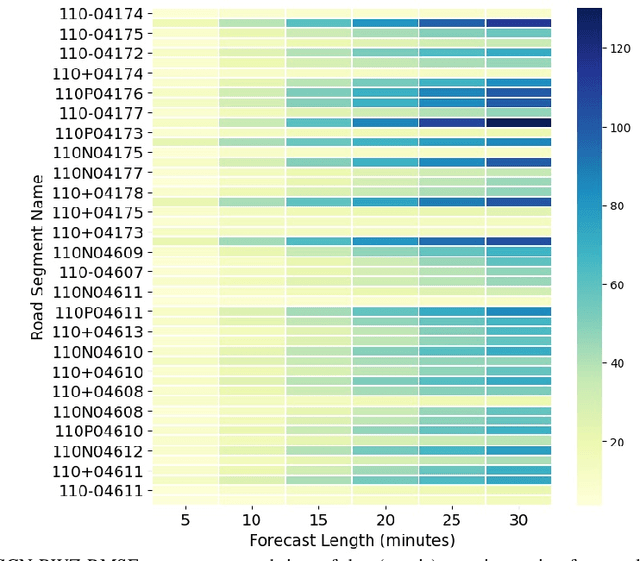
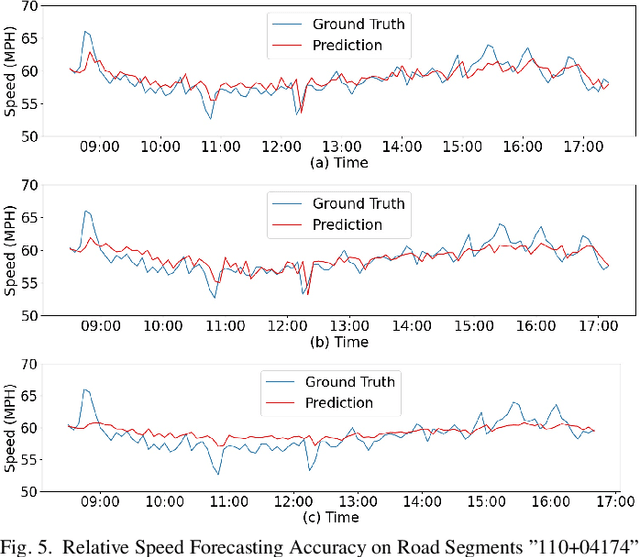
Forecasting traffic flows is a central task in intelligent transportation system management. Graph structures have shown promise as a modeling framework, with recent advances in spatio-temporal modeling via graph convolution neural networks, improving the performance or extending the prediction horizon on traffic flows. However, a key shortcoming of state-of-the-art methods is their inability to take into account information of various modalities, for instance the impact of maintenance downtime on traffic flows. This is the issue we address in this paper. Specifically, we propose a novel model to predict traffic speed under the impact of construction work. The model is based on the powerful attention-based spatio-temporal graph convolution architecture but utilizes various channels to integrate different sources of information, explicitly builds spatio-temporal dependencies among traffic states, captures the relationships between heterogeneous roadway networks, and then predicts changes in traffic flow resulting from maintenance downtime events. The model is evaluated on two benchmark datasets and a novel dataset we have collected over the bustling Tyson's corner region in Northern Virginia. Extensive comparative experiments and ablation studies show that the proposed model can capture complex and nonlinear spatio-temporal relationships across a transportation corridor, outperforming baseline models.
Bridge type classification: supervised learning on a modified NBI dataset
Feb 12, 2018
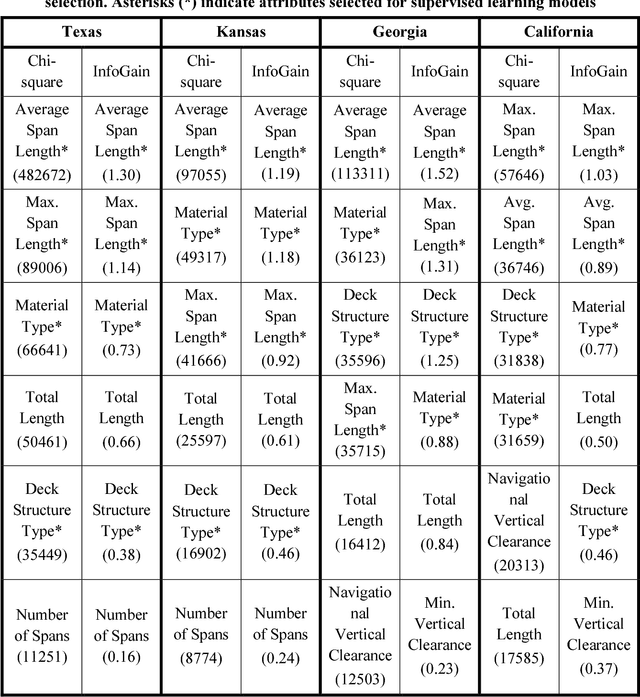
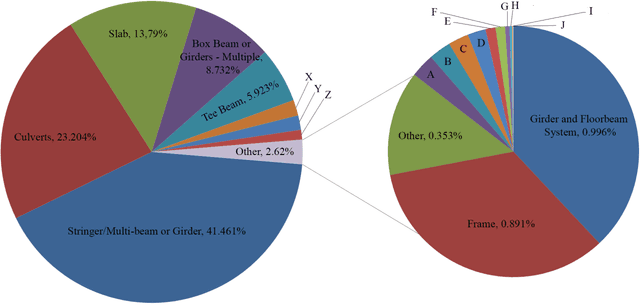
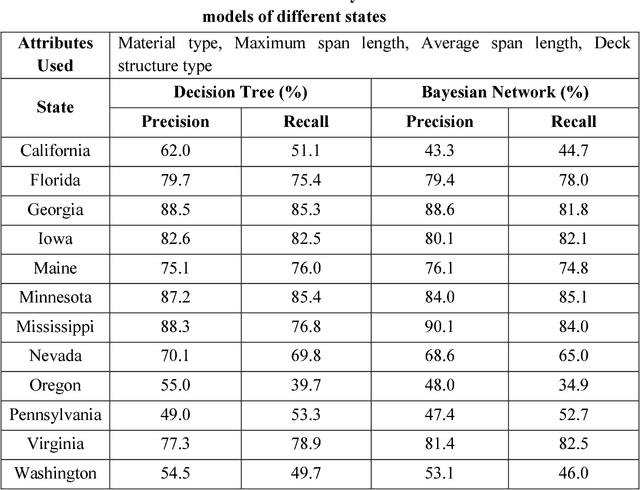
A key phase in the bridge design process is the selection of the structural system. Due to budget and time constraints, engineers typically rely on engineering judgment and prior experience when selecting a structural system, often considering a limited range of design alternatives. The objective of this study was to explore the suitability of supervised machine learning as a preliminary design aid that provides guidance to engineers with regards to the statistically optimal bridge type to choose, ultimately improving the likelihood of optimized design, design standardization, and reduced maintenance costs. In order to devise this supervised learning system, data for over 600,000 bridges from the National Bridge Inventory database were analyzed. Key attributes for determining the bridge structure type were identified through three feature selection techniques. Potentially useful attributes like seismic intensity and historic data on the cost of materials (steel and concrete) were then added from the US Geological Survey (USGS) database and Engineering News Record. Decision tree, Bayes network and Support Vector Machines were used for predicting the bridge design type. Due to state-to-state variations in material availability, material costs, and design codes, supervised learning models based on the complete data set did not yield favorable results. Supervised learning models were then trained and tested using 10-fold cross validation on data for each state. Inclusion of seismic data improved the model performance noticeably. The data was then resampled to reduce the bias of the models towards more common design types, and the supervised learning models thus constructed showed further improvements in performance. The average recall and precision for the state models was 88.6% and 88.0% using Decision Trees, 84.0% and 83.7% using Bayesian Networks, and 80.8% and 75.6% using SVM.
* Preprint of paper published in ASCE Journal of Computing (https://ascelibrary.org/doi/full/10.1061/(ASCE)CP.1943-5487.0000712). 6 figures and 8 tables, provided at end of document