 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANCHOR: Integrating Adversarial Training with Hard-mined Supervised Contrastive Learning for Robust Representation Learning
Oct 31, 2025Neural networks have changed the way machines interpret the world. At their core, they learn by following gradients, adjusting their parameters step by step until they identify the most discriminant patterns in the data. This process gives them their strength, yet it also opens the door to a hidden flaw. The very gradients that help a model learn can also be used to produce small, imperceptible tweaks that cause the model to completely alter its decision. Such tweaks are called adversarial attacks. These attacks exploit this vulnerability by adding tiny, imperceptible changes to images that, while leaving them identical to the human eye, cause the model to make wrong predictions. In this work, we propose Adversarially-trained Contrastive Hard-mining for Optimized Robustness (ANCHOR), a framework that leverages the power of supervised contrastive learning with explicit hard positive mining to enable the model to learn representations for images such that the embeddings for the images, their augmentations, and their perturbed versions cluster together in the embedding space along with those for other images of the same class while being separated from images of other classes. This alignment helps the model focus on stable, meaningful patterns rather than fragile gradient cues. On CIFAR-10, our approach achieves impressive results for both clean and robust accuracy under PGD-20 (epsilon = 0.031), outperforming standard adversarial training methods. Our results indicate that combining adversarial guidance with hard-mined contrastive supervision helps models learn more structured and robust representations, narrowing the gap between accuracy and robustness.
Multi-hop Question Answering over Knowledge Graphs using Large Language Models
Apr 30, 2024
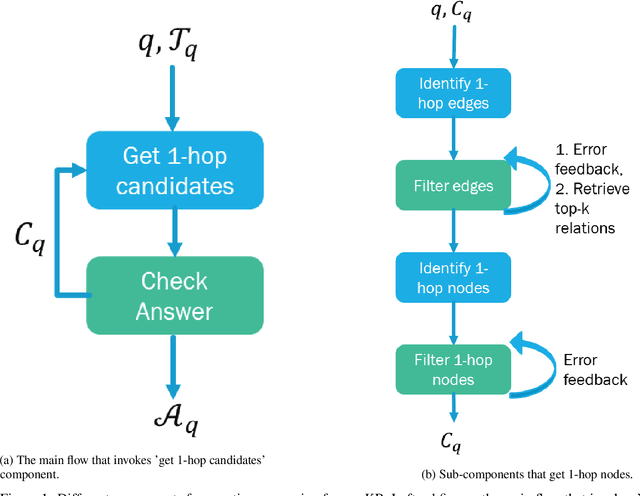


Knowledge graphs (KGs) are large datasets with specific structures representing large knowledge bases (KB) where each node represents a key entity and relations amongst them are typed edges. Natural language queries formed to extract information from a KB entail starting from specific nodes and reasoning over multiple edges of the corresponding KG to arrive at the correct set of answer nodes. Traditional approaches of question answering on KG are based on (a) semantic parsing (SP), where a logical form (e.g., S-expression, SPARQL query, etc.) is generated using node and edge embeddings and then reasoning over these representations or tuning language models to generate the final answer directly, or (b) information-retrieval based that works by extracting entities and relations sequentially. In this work, we evaluate the capability of (LLMs) to answer questions over KG that involve multiple hops. We show that depending upon the size and nature of the KG we need different approaches to extract and feed the relevant information to an LLM since every LLM comes with a fixed context window. We evaluate our approach on six KGs with and without the availability of example-specific sub-graphs and show that both the IR and SP-based methods can be adopted by LLMs resulting in an extremely competitive performance.
Aspect and Opinion Term Extraction Using Graph Attention Network
Apr 30, 2024



In this work we investigate the capability of Graph Attention Network for extracting aspect and opinion terms. Aspect and opinion term extraction is posed as a token-level classification task akin to named entity recognition. We use the dependency tree of the input query as additional feature in a Graph Attention Network along with the token and part-of-speech features. We show that the dependency structure is a powerful feature that in the presence of a CRF layer substantially improves the performance and generates the best result on the commonly used datasets from SemEval 2014, 2015 and 2016. We experiment with additional layers like BiLSTM and Transformer in addition to the CRF layer. We also show that our approach works well in the presence of multiple aspects or sentiments in the same query and it is not necessary to modify the dependency tree based on a single aspect as was the original application for sentiment classification.
The RL/LLM Taxonomy Tree: Reviewing Synergies Between Reinforcement Learning and Large Language Models
Feb 02, 2024In this work, we review research studies that combine Reinforcement Learning (RL) and Large Language Models (LLMs), two areas that owe their momentum to the development of deep neural networks. We propose a novel taxonomy of three main classes based on the way that the two model types interact with each other. The first class, RL4LLM, includes studies where RL is leveraged to improve the performance of LLMs on tasks related to Natural Language Processing. L4LLM is divided into two sub-categories depending on whether RL is used to directly fine-tune an existing LLM or to improve the prompt of the LLM. In the second class, LLM4RL, an LLM assists the training of an RL model that performs a task that is not inherently related to natural language. We further break down LLM4RL based on the component of the RL training framework that the LLM assists or replaces, namely reward shaping, goal generation, and policy function. Finally, in the third class, RL+LLM, an LLM and an RL agent are embedded in a common planning framework without either of them contributing to training or fine-tuning of the other. We further branch this class to distinguish between studies with and without natural language feedback. We use this taxonomy to explore the motivations behind the synergy of LLMs and RL and explain the reasons for its success, while pinpointing potential shortcomings and areas where further research is needed, as well as alternative methodologies that serve the same goal.
Aspect Based Sentiment Analysis Using Spectral Temporal Graph Neural Network
Feb 14, 2022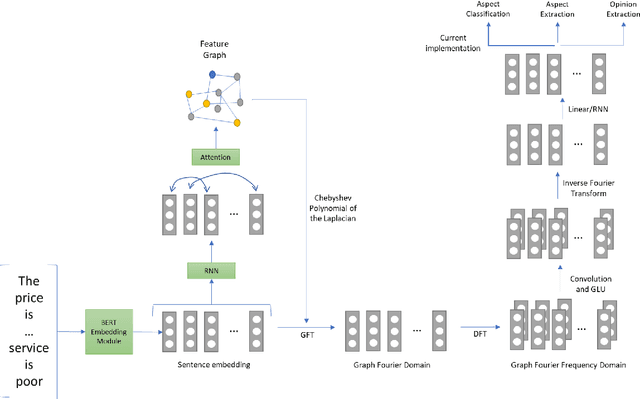
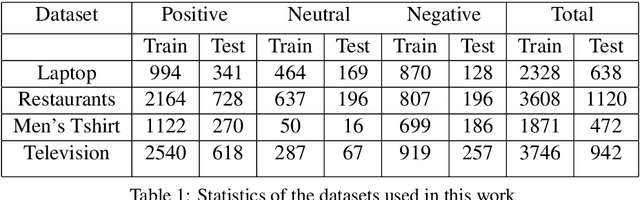
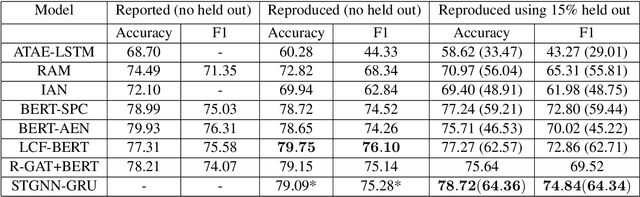

The objective of Aspect Based Sentiment Analysis is to capture the sentiment of reviewers associated with different aspects. However, complexity of the review sentences, presence of double negation and specific usage of words found in different domains make it difficult to predict the sentiment accurately and overall a challenging natural language understanding task. While recurrent neural network, attention mechanism and more recently, graph attention based models are prevalent, in this paper we propose graph Fourier transform based network with features created in the spectral domain. While this approach has found considerable success in the forecasting domain, it has not been explored earlier for any natural language processing task. The method relies on creating and learning an underlying graph from the raw data and thereby using the adjacency matrix to shift to the graph Fourier domain. Subsequently, Fourier transform is used to switch to the frequency (spectral) domain where new features are created. These series of transformation proved to be extremely efficient in learning the right representation as we have found that our model achieves the best result on both the SemEval-2014 datasets, i.e., "Laptop" and "Restaurants" domain. Our proposed model also found competitive results on the two other recently proposed datasets from the e-commerce domain.