 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-hop Question Answering over Knowledge Graphs using Large Language Models
Paper and Code
Apr 30, 2024
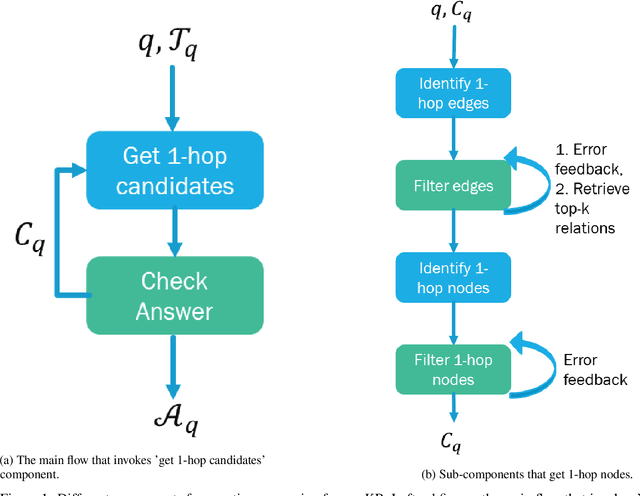


Knowledge graphs (KGs) are large datasets with specific structures representing large knowledge bases (KB) where each node represents a key entity and relations amongst them are typed edges. Natural language queries formed to extract information from a KB entail starting from specific nodes and reasoning over multiple edges of the corresponding KG to arrive at the correct set of answer nodes. Traditional approaches of question answering on KG are based on (a) semantic parsing (SP), where a logical form (e.g., S-expression, SPARQL query, etc.) is generated using node and edge embeddings and then reasoning over these representations or tuning language models to generate the final answer directly, or (b) information-retrieval based that works by extracting entities and relations sequentially. In this work, we evaluate the capability of (LLMs) to answer questions over KG that involve multiple hops. We show that depending upon the size and nature of the KG we need different approaches to extract and feed the relevant information to an LLM since every LLM comes with a fixed context window. We evaluate our approach on six KGs with and without the availability of example-specific sub-graphs and show that both the IR and SP-based methods can be adopted by LLMs resulting in an extremely competitive performance.