 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Learning for OCR Text Correction
Nov 21, 2016

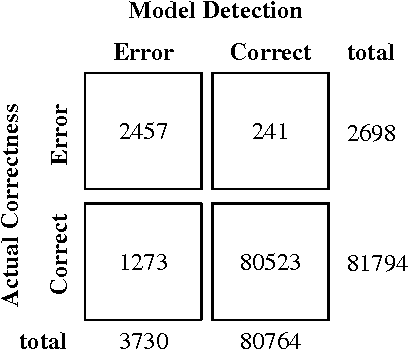

The accuracy of Optical Character Recognition (OCR) is crucial to the success of subsequent applications used in text analyzing pipeline. Recent models of OCR post-processing significantly improve the quality of OCR-generated text, but are still prone to suggest correction candidates from limited observations while insufficiently accounting for the characteristics of OCR errors. In this paper, we show how to enlarge candidate suggestion space by using external corpus and integrating OCR-specific features in a regression approach to correct OCR-generated errors. The evaluation results show that our model can correct 61.5% of the OCR-errors (considering the top 1 suggestion) and 71.5% of the OCR-errors (considering the top 3 suggestions), for cases where the theoretical correction upper-bound is 78%.
Semi-supervised Clustering Ensemble by Voting
Aug 20, 2012

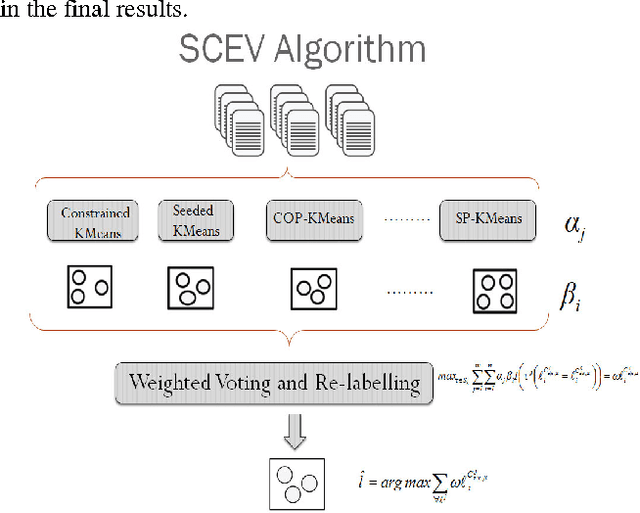

Clustering ensemble is one of the most recent advances in unsupervised learning. It aims to combine the clustering results obtained using different algorithms or from different runs of the same clustering algorithm for the same data set, this is accomplished using on a consensus function, the efficiency and accuracy of this method has been proven in many works in literature. In the first part of this paper we make a comparison among current approaches to clustering ensemble in literature. All of these approaches consist of two main steps: the ensemble generation and consensus function. In the second part of the paper, we suggest engaging supervision in the clustering ensemble procedure to get more enhancements on the clustering results. Supervision can be applied in two places: either by using semi-supervised algorithms in the clustering ensemble generation step or in the form of a feedback used by the consensus function stage. Also, we introduce a flexible two parameter weighting mechanism, the first parameter describes the compatibility between the datasets under study and the semi-supervised clustering algorithms used to generate the base partitions, the second parameter is used to provide the user feedback on the these partitions. The two parameters are engaged in a "relabeling and voting" based consensus function to produce the final clustering.