 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePremise-Augmented Reasoning Chains Improve Error Identification in Math reasoning with LLMs
Feb 06, 2025Chain-of-Thought (CoT) prompting enhances mathematical reasoning in large language models (LLMs) by enabling detailed step-by-step solutions. However, due to the verbosity of LLMs, the resulting reasoning chains can be long, making it harder to verify the reasoning steps and trace issues resulting from dependencies between the steps that may be farther away in the sequence of steps. Importantly, mathematical reasoning allows each step to be derived from a small set of premises, which are a subset of the preceding steps in the reasoning chain. In this paper, we present a framework that identifies the premises for each step, to improve the evaluation of reasoning. We restructure conventional linear reasoning chains into Premise Augmented Reasoning Chains (PARC) by introducing premise links, resulting in a directed acyclic graph where the nodes are the steps and the edges are the premise links. Through experiments with a PARC-based dataset that we built, namely PERL (Premises and ERrors identification in LLMs), we demonstrate that LLMs can reliably identify premises within complex reasoning chains. In particular, even open-source LLMs achieve 90% recall in premise identification. We also show that PARC helps to identify errors in reasoning chains more reliably. The accuracy of error identification improves by 6% to 16% absolute when step-by-step verification is carried out in PARC under the premises. Our findings highlight the utility of premise-centric representations in addressing complex problem-solving tasks and open new avenues for improving the reliability of LLM-based reasoning evaluations.
Democratizing LLMs: An Exploration of Cost-Performance Trade-offs in Self-Refined Open-Source Models
Oct 22, 2023

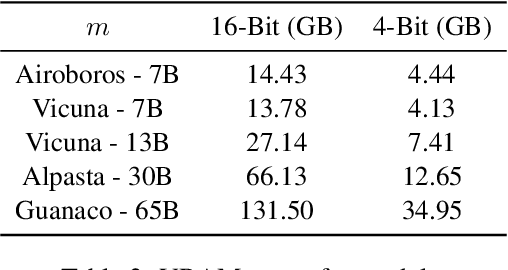
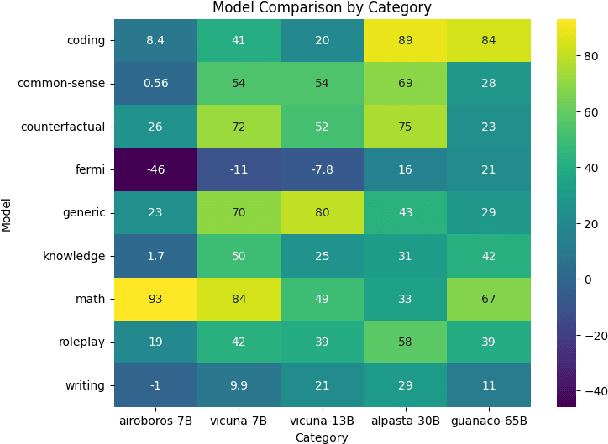
The dominance of proprietary LLMs has led to restricted access and raised information privacy concerns. High-performing open-source alternatives are crucial for information-sensitive and high-volume applications but often lag behind in performance. To address this gap, we propose (1) A untargeted variant of iterative self-critique and self-refinement devoid of external influence. (2) A novel ranking metric - Performance, Refinement, and Inference Cost Score (PeRFICS) - to find the optimal model for a given task considering refined performance and cost. Our experiments show that SoTA open source models of varying sizes from 7B - 65B, on average, improve 8.2% from their baseline performance. Strikingly, even models with extremely small memory footprints, such as Vicuna-7B, show a 11.74% improvement overall and up to a 25.39% improvement in high-creativity, open ended tasks on the Vicuna benchmark. Vicuna-13B takes it a step further and outperforms ChatGPT post-refinement. This work has profound implications for resource-constrained and information-sensitive environments seeking to leverage LLMs without incurring prohibitive costs, compromising on performance and privacy. The domain-agnostic self-refinement process coupled with our novel ranking metric facilitates informed decision-making in model selection, thereby reducing costs and democratizing access to high-performing language models, as evidenced by case studies.