 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Driven AI Sensors: Secure Healthcare Monitoring with PUFs
Jun 05, 2025



Wearable and implantable healthcare sensors are pivotal for real-time patient monitoring but face critical challenges in power efficiency, data security, and signal noise. This paper introduces a novel platform that leverages hardware noise as a dual-purpose resource to enhance machine learning (ML) robustness and secure data via Physical Unclonable Functions (PUFs). By integrating noise-driven signal processing, PUFbased authentication, and ML-based anomaly detection, our system achieves secure, low-power monitoring for devices like ECG wearables. Simulations demonstrate that noise improves ML accuracy by 8% (92% for detecting premature ventricular contractions (PVCs) and atrial fibrillation (AF)), while PUFs provide 98% uniqueness for tamper-resistant security, all within a 50 uW power budget. This unified approach not only addresses power, security, and noise challenges but also enables scalable, intelligent sensing for telemedicine and IoT applications.
Re-evaluation of Face Anti-spoofing Algorithm in Post COVID-19 Era Using Mask Based Occlusion Attack
Aug 23, 2024



Face anti-spoofing algorithms play a pivotal role in the robust deployment of face recognition systems against presentation attacks. Conventionally, full facial images are required by such systems to correctly authenticate individuals, but the widespread requirement of masks due to the current COVID-19 pandemic has introduced new challenges for these biometric authentication systems. Hence, in this work, we investigate the performance of presentation attack detection (PAD) algorithms under synthetic facial occlusions using masks and glasses. We have used five variants of masks to cover the lower part of the face with varying coverage areas (low-coverage, medium-coverage, high-coverage, round coverage), and 3D cues. We have also used different variants of glasses that cover the upper part of the face. We systematically tested the performance of four PAD algorithms under these occlusion attacks using a benchmark dataset. We have specifically looked at four different baseline PAD algorithms that focus on, texture, image quality, frame difference/motion, and abstract features through a convolutional neural network (CNN). Additionally we have introduced a new hybrid model that uses CNN and local binary pattern textures. Our experiment shows that adding the occlusions significantly degrades the performance of all of the PAD algorithms. Our results show the vulnerability of face anti-spoofing algorithms with occlusions, which could be in the usage of such algorithms in the post-pandemic era.
GAN-based Deidentification of Drivers' Face Videos: An Assessment of Human Factors Implications in NDS Data
Jun 04, 2023



This paper addresses the problem of sharing drivers' face videos for transportation research while adhering to proper ethical guidelines. The paper first gives an overview of the multitude of problems associated with sharing such data and then proposes a framework on how artificial intelligence-based techniques, specifically face swapping, can be used for de-identifying drivers' faces. Through extensive experimentation with an Oak Ridge National Laboratory (ORNL) dataset, we demonstrate the effectiveness of face-swapping algorithms in preserving essential attributes related to human factors research, including eye movements, head movements, and mouth movements. The efficacy of the framework was also tested on various naturalistic driving study data collected at the Virginia Tech Transportation Institute. The results achieved through the proposed techniques were evaluated qualitatively and quantitatively using various metrics. Finally, we discuss possible measures for sharing the de-identified videos with the greater research community.
Color Invariant Skin Segmentation
Apr 22, 2022
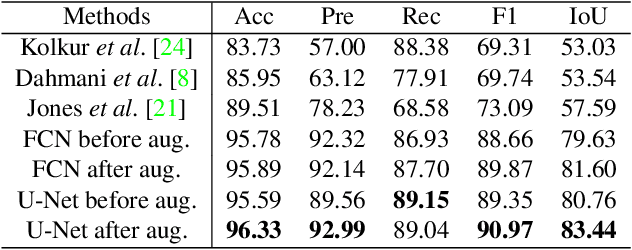
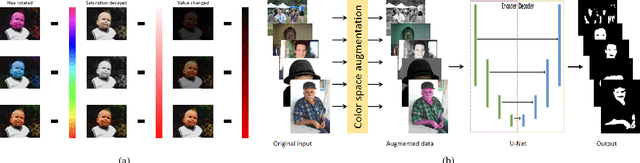

This paper addresses the problem of automatically detecting human skin in images without reliance on color information. A primary motivation of the work has been to achieve results that are consistent across the full range of skin tones, even while using a training dataset that is significantly biased toward lighter skin tones. Previous skin-detection methods have used color cues almost exclusively, and we present a new approach that performs well in the absence of such information. A key aspect of the work is dataset repair through augmentation that is applied strategically during training, with the goal of color invariant feature learning to enhance generalization. We have demonstrated the concept using two architectures, and experimental results show improvements in both precision and recall for most Fitzpatrick skin tones in the benchmark ECU dataset. We further tested the system with the RFW dataset to show that the proposed method performs much more consistently across different ethnicities, thereby reducing the chance of bias based on skin color. To demonstrate the effectiveness of our work, extensive experiments were performed on grayscale images as well as images obtained under unconstrained illumination and with artificial filters. Source code: https://github.com/HanXuMartin/Color-Invariant-Skin-Segmentation
GCNNMatch: Graph Convolutional Neural Networks for Multi-Object Tracking via Sinkhorn Normalization
Oct 07, 2020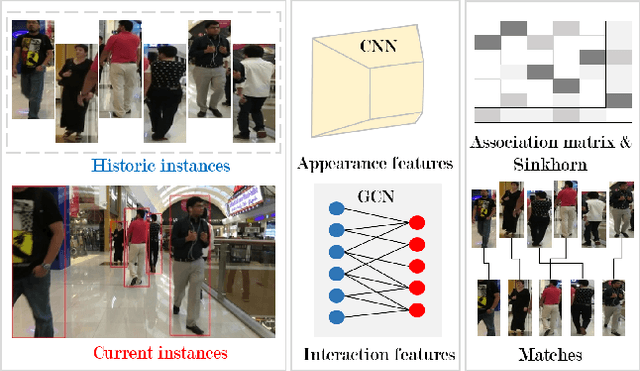

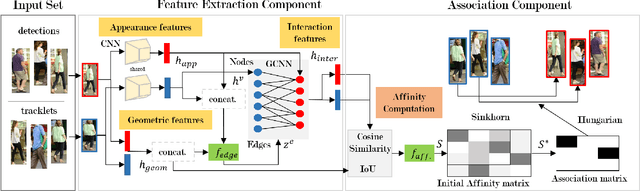

This paper proposes a novel method for online Multi-Object Tracking (MOT) using Graph Convolutional Neural Network (GCNN) based feature extraction and end-to-end feature matching for object association. The Graph based approach incorporates both appearance and geometry of objects at past frames as well as the current frame into the task of feature learning. This new paradigm enables the network to leverage the "context" information of the geometry of objects and allows us to model the interactions among the features of multiple objects. Another central innovation of our proposed framework is the use of the Sinkhorn algorithm for end-to-end learning of the associations among objects during model training. The network is trained to predict object associations by taking into account constraints specific to the MOT task. Experimental results demonstrate the efficacy of the proposed approach in achieving top performance on the MOT16 & 17 Challenge problems among state-of-the-art online and supervised approaches. The code is available at https://github.com/IPapakis/GCNNMatch.