 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Risk in Reinforcement Learning: A Literature Mapping
Dec 08, 2023



Safe reinforcement learning deals with mitigating or avoiding unsafe situations by reinforcement learning (RL) agents. Safe RL approaches are based on specific risk representations for particular problems or domains. In order to analyze agent behaviors, compare safe RL approaches, and effectively transfer techniques between application domains, it is necessary to understand the types of risk specific to safe RL problems. We performed a systematic literature mapping with the objective to characterize risk in safe RL. Based on the obtained results, we present definitions, characteristics, and types of risk that hold on multiple application domains. Our literature mapping covers literature from the last 5 years (2017-2022), from a variety of knowledge areas (AI, finance, engineering, medicine) where RL approaches emphasize risk representation and management. Our mapping covers 72 papers filtered systematically from over thousands of papers on the topic. Our proposed notion of risk covers a variety of representations, disciplinary differences, common training exercises, and types of techniques. We encourage researchers to include explicit and detailed accounts of risk in future safe RL research reports, using this mapping as a starting point. With this information, researchers and practitioners could draw stronger conclusions on the effectiveness of techniques on different problems.
Towards Action Model Learning for Player Modeling
Mar 09, 2021
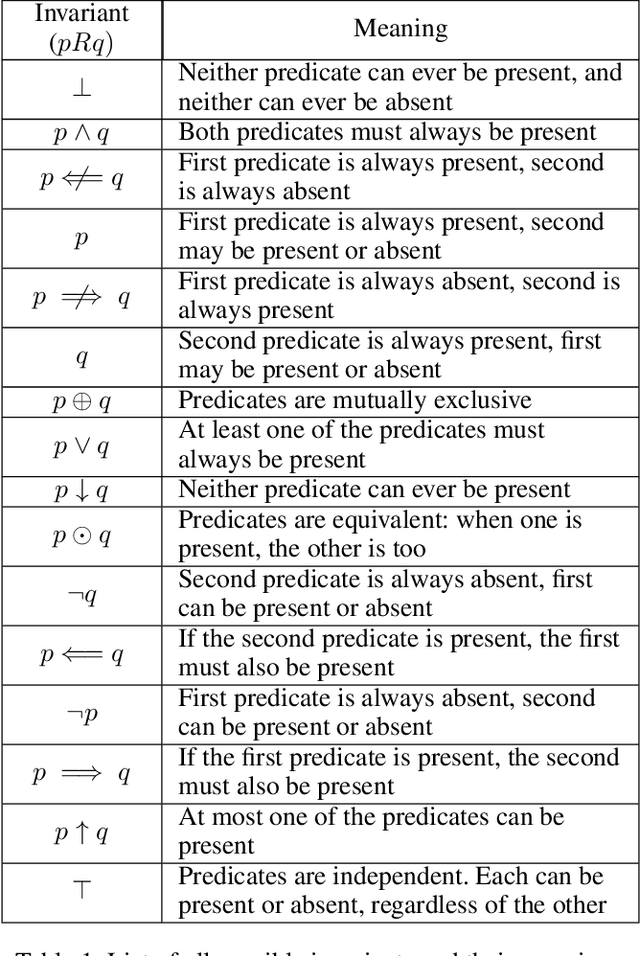

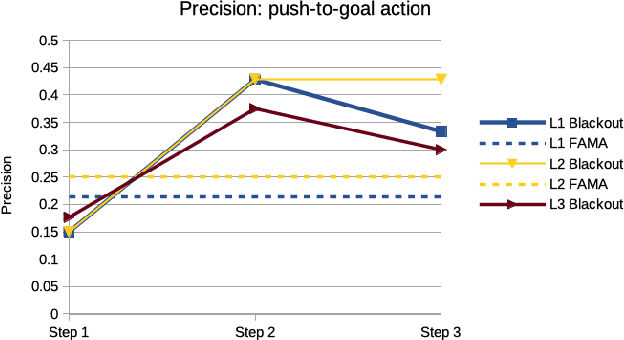
Player modeling attempts to create a computational model which accurately approximates a player's behavior in a game. Most player modeling techniques rely on domain knowledge and are not transferable across games. Additionally, player models do not currently yield any explanatory insight about a player's cognitive processes, such as the creation and refinement of mental models. In this paper, we present our findings with using action model learning (AML), in which an action model is learned given data in the form of a play trace, to learn a player model in a domain-agnostic manner. We demonstrate the utility of this model by introducing a technique to quantitatively estimate how well a player understands the mechanics of a game. We evaluate an existing AML algorithm (FAMA) for player modeling and develop a novel algorithm called Blackout that is inspired by player cognition. We compare Blackout with FAMA using the puzzle game Sokoban and show that Blackout generates better player models.
* 7 pages, 1 figure