 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight G-YOLOv11: Advancing Efficient Fracture Detection in Pediatric Wrist X-rays
Dec 31, 2024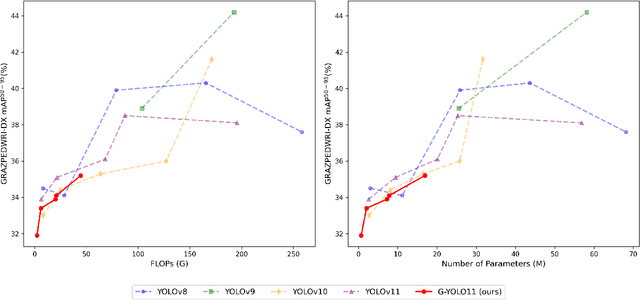

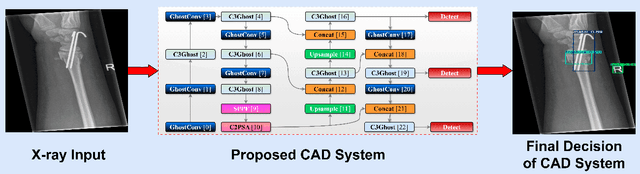

Computer-aided diagnosis (CAD) systems have greatly improved the interpretation of medical images by radiologists and surgeons. However, current CAD systems for fracture detection in X-ray images primarily rely on large, resource-intensive detectors, which limits their practicality in clinical settings. To address this limitation, we propose a novel lightweight CAD system based on the YOLO detector for fracture detection. This system, named ghost convolution-based YOLOv11 (G-YOLOv11), builds on the latest version of the YOLO detector family and incorporates the ghost convolution operation for feature extraction. The ghost convolution operation generates the same number of feature maps as traditional convolution but requires fewer linear operations, thereby reducing the detector's computational resource requirements. We evaluated the performance of the proposed G-YOLOv11 detector on the GRAZPEDWRI-DX dataset, achieving an mAP@0.5 of 0.535 with an inference time of 2.4 ms on an NVIDIA A10 GPU. Compared to the standard YOLOv11l, G-YOLOv11l achieved reductions of 13.6% in mAP@0.5 and 68.7% in size. These results establish a new state-of-the-art benchmark in terms of efficiency, outperforming existing detectors. Code and models are available at https://github.com/AbdesselamFerdi/G-YOLOv11.
Deep Convolutional Neural Networks Structured Pruning via Gravity Regularization
Nov 25, 2024Structured pruning is a widely employed strategy for accelerating deep convolutional neural networks (DCNNs). However, existing methods often necessitate modifications to the original architectures, involve complex implementations, and require lengthy fine-tuning stages. To address these challenges, we propose a novel physics-inspired approach that integrates the concept of gravity into the training stage of DCNNs. In this approach, the gravity is directly proportional to the product of the masses of the convolution filter and the attracting filter, and inversely proportional to the square of the distance between them. We applied this force to the convolution filters, either drawing filters closer to the attracting filter (experiencing weaker gravity) toward non-zero weights or pulling filters farther away (subject to stronger gravity) toward zero weights. As a result, filters experiencing stronger gravity have their weights reduced to zero, enabling their removal, while filters under weaker gravity retain significant weights and preserve important information. Our method simultaneously optimizes the filter weights and ranks their importance, eliminating the need for complex implementations or extensive fine-tuning. We validated the proposed approach on popular DCNN architectures using the CIFAR dataset, achieving competitive results compared to existing methods.
Electrostatic Force Regularization for Neural Structured Pruning
Nov 17, 2024



The demand for deploying deep convolutional neural networks (DCNNs) on resource-constrained devices for real-time applications remains substantial. However, existing state-of-the-art structured pruning methods often involve intricate implementations, require modifications to the original network architectures, and necessitate an extensive fine-tuning phase. To overcome these challenges, we propose a novel method that, for the first time, incorporates the concepts of charge and electrostatic force from physics into the training process of DCNNs. The magnitude of this force is directly proportional to the product of the charges of the convolution filter and the source filter, and inversely proportional to the square of the distance between them. We applied this electrostatic-like force to the convolution filters, either attracting filters with opposite charges toward non-zero weights or repelling filters with like charges toward zero weights. Consequently, filters subject to repulsive forces have their weights reduced to zero, enabling their removal, while the attractive forces preserve filters with significant weights that retain information. Unlike conventional methods, our approach is straightforward to implement, does not require any architectural modifications, and simultaneously optimizes weights and ranks filter importance, all without the need for extensive fine-tuning. We validated the efficacy of our method on modern DCNN architectures using the MNIST, CIFAR, and ImageNet datasets, achieving competitive performance compared to existing structured pruning approaches.