 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Sentiment Analysis for Low Resource languages Using Data Augmentation Approaches: A Case Study in Marathi
Oct 01, 2023

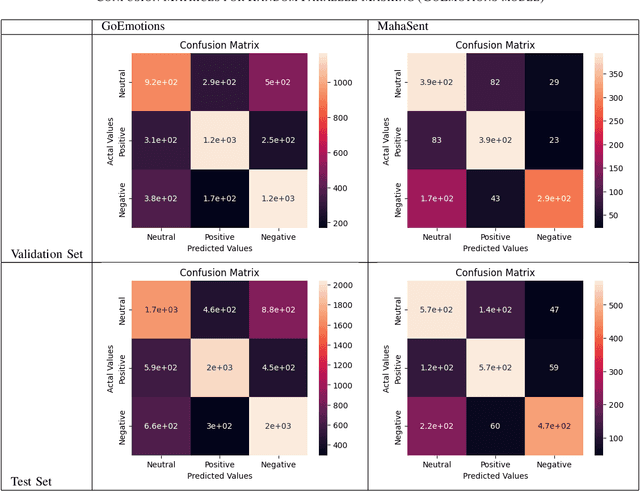
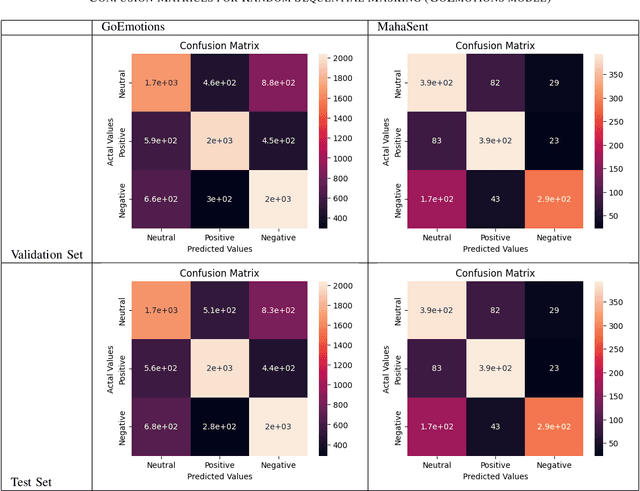
Sentiment analysis plays a crucial role in understanding the sentiment expressed in text data. While sentiment analysis research has been extensively conducted in English and other Western languages, there exists a significant gap in research efforts for sentiment analysis in low-resource languages. Limited resources, including datasets and NLP research, hinder the progress in this area. In this work, we present an exhaustive study of data augmentation approaches for the low-resource Indic language Marathi. Although domain-specific datasets for sentiment analysis in Marathi exist, they often fall short when applied to generalized and variable-length inputs. To address this challenge, this research paper proposes four data augmentation techniques for sentiment analysis in Marathi. The paper focuses on augmenting existing datasets to compensate for the lack of sufficient resources. The primary objective is to enhance sentiment analysis model performance in both in-domain and cross-domain scenarios by leveraging data augmentation strategies. The data augmentation approaches proposed showed a significant performance improvement for cross-domain accuracies. The augmentation methods include paraphrasing, back-translation; BERT-based random token replacement, named entity replacement, and pseudo-label generation; GPT-based text and label generation. Furthermore, these techniques can be extended to other low-resource languages and for general text classification tasks.
L3Cube-MahaSent-MD: A Multi-domain Marathi Sentiment Analysis Dataset and Transformer Models
Jun 24, 2023



The exploration of sentiment analysis in low-resource languages, such as Marathi, has been limited due to the availability of suitable datasets. In this work, we present L3Cube-MahaSent-MD, a multi-domain Marathi sentiment analysis dataset, with four different domains - movie reviews, general tweets, TV show subtitles, and political tweets. The dataset consists of around 60,000 manually tagged samples covering 3 distinct sentiments - positive, negative, and neutral. We create a sub-dataset for each domain comprising 15k samples. The MahaSent-MD is the first comprehensive multi-domain sentiment analysis dataset within the Indic sentiment landscape. We fine-tune different monolingual and multilingual BERT models on these datasets and report the best accuracy with the MahaBERT model. We also present an extensive in-domain and cross-domain analysis thus highlighting the need for low-resource multi-domain datasets. The data and models are available at https://github.com/l3cube-pune/MarathiNLP .
Implementing Deep Learning-Based Approaches for Article Summarization in Indian Languages
Dec 12, 2022

The research on text summarization for low-resource Indian languages has been limited due to the availability of relevant datasets. This paper presents a summary of various deep-learning approaches used for the ILSUM 2022 Indic language summarization datasets. The ISUM 2022 dataset consists of news articles written in Indian English, Hindi, and Gujarati respectively, and their ground-truth summarizations. In our work, we explore different pre-trained seq2seq models and fine-tune those with the ILSUM 2022 datasets. In our case, the fine-tuned SoTA PEGASUS model worked the best for English, the fine-tuned IndicBART model with augmented data for Hindi, and again fine-tuned PEGASUS model along with a translation mapping-based approach for Gujarati. Our scores on the obtained inferences were evaluated using ROUGE-1, ROUGE-2, and ROUGE-4 as the evaluation metrics.