 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Sentiment Analysis for Low Resource languages Using Data Augmentation Approaches: A Case Study in Marathi
Paper and Code
Oct 01, 2023

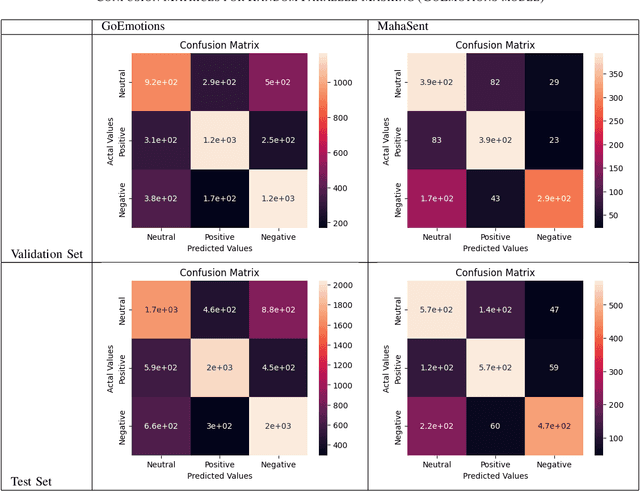
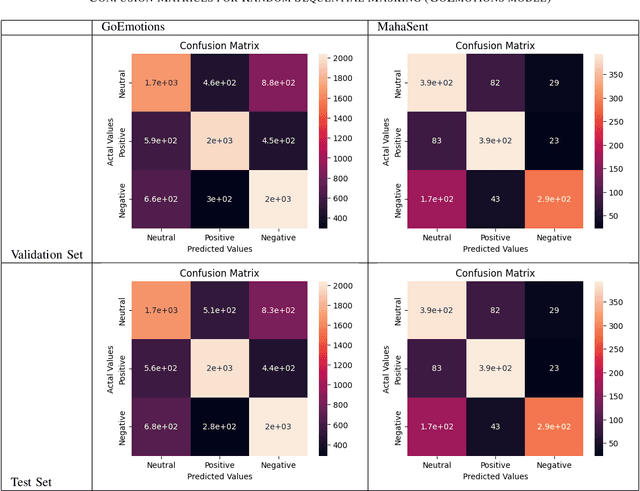
Sentiment analysis plays a crucial role in understanding the sentiment expressed in text data. While sentiment analysis research has been extensively conducted in English and other Western languages, there exists a significant gap in research efforts for sentiment analysis in low-resource languages. Limited resources, including datasets and NLP research, hinder the progress in this area. In this work, we present an exhaustive study of data augmentation approaches for the low-resource Indic language Marathi. Although domain-specific datasets for sentiment analysis in Marathi exist, they often fall short when applied to generalized and variable-length inputs. To address this challenge, this research paper proposes four data augmentation techniques for sentiment analysis in Marathi. The paper focuses on augmenting existing datasets to compensate for the lack of sufficient resources. The primary objective is to enhance sentiment analysis model performance in both in-domain and cross-domain scenarios by leveraging data augmentation strategies. The data augmentation approaches proposed showed a significant performance improvement for cross-domain accuracies. The augmentation methods include paraphrasing, back-translation; BERT-based random token replacement, named entity replacement, and pseudo-label generation; GPT-based text and label generation. Furthermore, these techniques can be extended to other low-resource languages and for general text classification tasks.