 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTQCompressor: improving tensor decomposition methods in neural networks via permutations
Jan 29, 2024

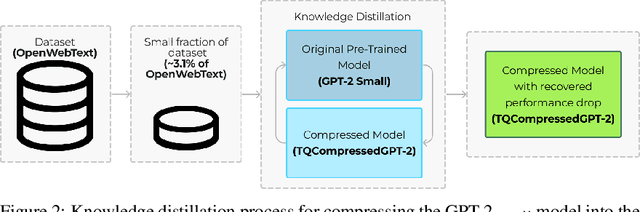

We introduce TQCompressor, a novel method for neural network model compression with improved tensor decompositions. We explore the challenges posed by the computational and storage demands of pre-trained language models in NLP tasks and propose a permutation-based enhancement to Kronecker decomposition. This enhancement makes it possible to reduce loss in model expressivity which is usually associated with factorization. We demonstrate this method applied to the GPT-2$_{small}$. The result of the compression is TQCompressedGPT-2 model, featuring 81 mln. parameters compared to 124 mln. in the GPT-2$_{small}$. We make TQCompressedGPT-2 publicly available. We further enhance the performance of the TQCompressedGPT-2 through a training strategy involving multi-step knowledge distillation, using only a 3.1% of the OpenWebText. TQCompressedGPT-2 surpasses DistilGPT-2 and KnGPT-2 in comparative evaluations, marking an advancement in the efficient and effective deployment of models in resource-constrained environments.
Tetra-AML: Automatic Machine Learning via Tensor Networks
Mar 28, 2023Neural networks have revolutionized many aspects of society but in the era of huge models with billions of parameters, optimizing and deploying them for commercial applications can require significant computational and financial resources. To address these challenges, we introduce the Tetra-AML toolbox, which automates neural architecture search and hyperparameter optimization via a custom-developed black-box Tensor train Optimization algorithm, TetraOpt. The toolbox also provides model compression through quantization and pruning, augmented by compression using tensor networks. Here, we analyze a unified benchmark for optimizing neural networks in computer vision tasks and show the superior performance of our approach compared to Bayesian optimization on the CIFAR-10 dataset. We also demonstrate the compression of ResNet-18 neural networks, where we use 14.5 times less memory while losing just 3.2% of accuracy. The presented framework is generic, not limited by computer vision problems, supports hardware acceleration (such as with GPUs and TPUs) and can be further extended to quantum hardware and to hybrid quantum machine learning models.
UVIP: Model-Free Approach to Evaluate Reinforcement Learning Algorithms
Jun 03, 2021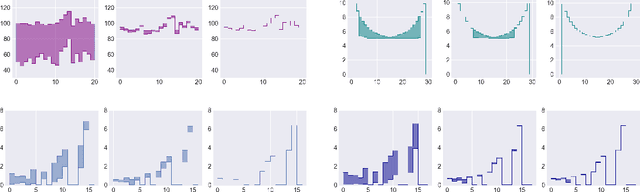
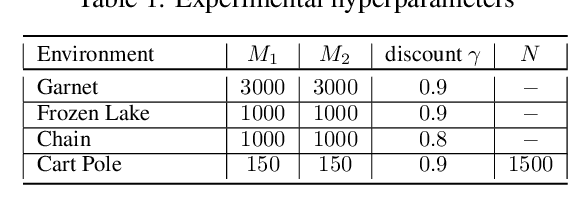
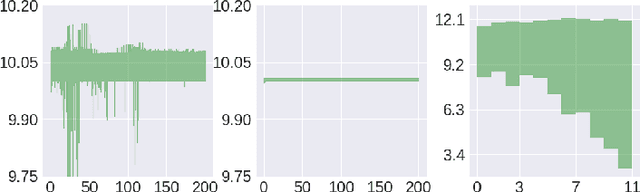
Policy evaluation is an important instrument for the comparison of different algorithms in Reinforcement Learning (RL). Yet even a precise knowledge of the value function $V^{\pi}$ corresponding to a policy $\pi$ does not provide reliable information on how far is the policy $\pi$ from the optimal one. We present a novel model-free upper value iteration procedure $({\sf UVIP})$ that allows us to estimate the suboptimality gap $V^{\star}(x) - V^{\pi}(x)$ from above and to construct confidence intervals for $V^\star$. Our approach relies on upper bounds to the solution of the Bellman optimality equation via martingale approach. We provide theoretical guarantees for ${\sf UVIP}$ under general assumptions and illustrate its performance on a number of benchmark RL problems.
Variance reduction for Markov chains with application to MCMC
Oct 08, 2019

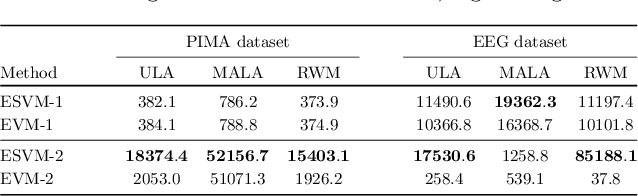
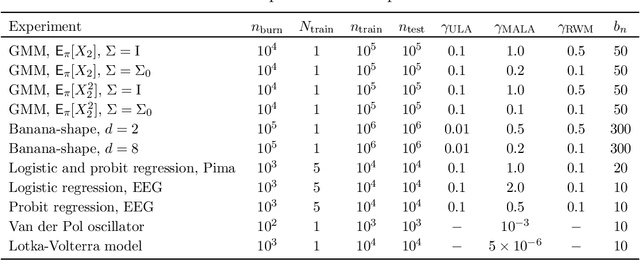
In this paper we propose a novel variance reduction approach for additive functionals of Markov chains based on minimization of an estimate for the asymptotic variance of these functionals over suitable classes of control variates. A distinctive feature of the proposed approach is its ability to significantly reduce the overall finite sample variance. This feature is theoretically demonstrated by means of a deep non asymptotic analysis of a variance reduced functional as well as by a thorough simulation study. In particular we apply our method to various MCMC Bayesian estimation problems where it favourably compares to the existing variance reduction approaches.