 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZooming into Face Forensics: A Pixel-level Analysis
Paper and Code
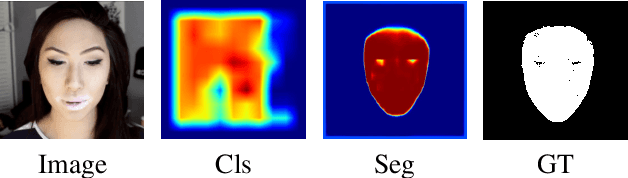
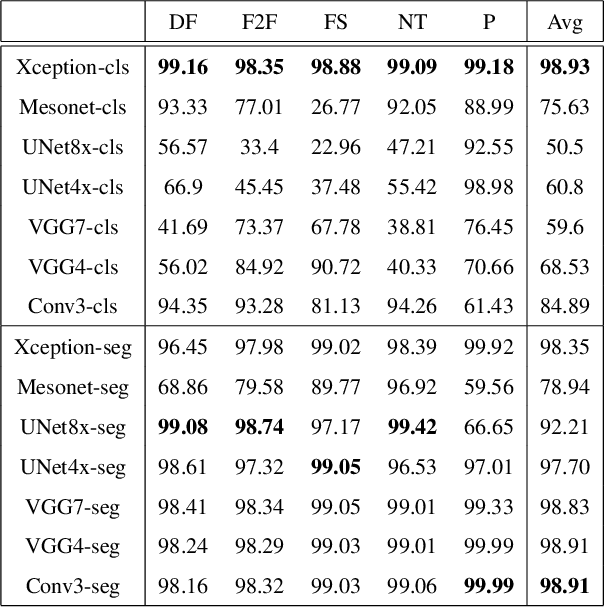


The stunning progress in face manipulation methods has made it possible to synthesize realistic fake face images, which poses potential threats to our society. It is urgent to have face forensics techniques to distinguish those tampered images. A large scale dataset "FaceForensics++" has provided enormous training data generated from prominent face manipulation methods to facilitate anti-fake research. However, previous works focus more on casting it as a classification problem by only considering a global prediction. Through investigation to the problem, we find that training a classification network often fails to capture high quality features, which might lead to sub-optimal solutions. In this paper, we zoom in on the problem by conducting a pixel-level analysis, i.e. formulating it as a pixel-level segmentation task. By evaluating multiple architectures on both segmentation and classification tasks, We show the superiority of viewing the problem from a segmentation perspective. Different ablation studies are also performed to investigate what makes an effective and efficient anti-fake model. Strong baselines are also established, which, we hope, could shed some light on the field of face forensics.