 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Learn Once: Universal Anatomical Landmark Detection
Paper and Code
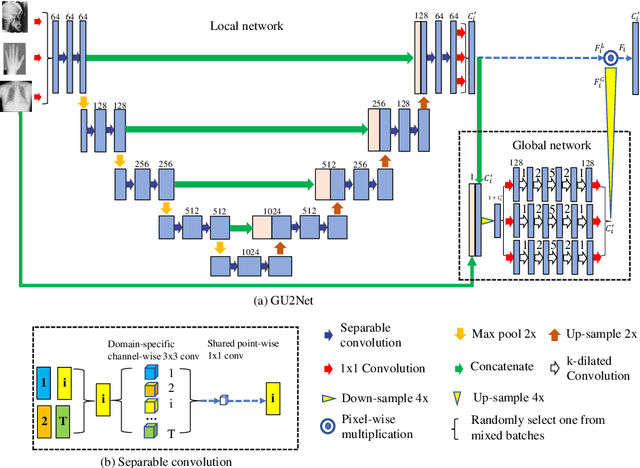
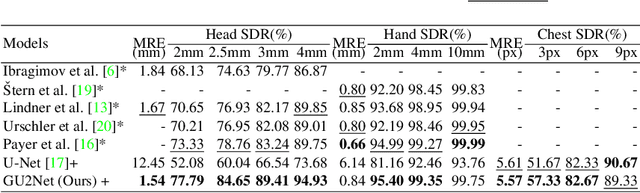
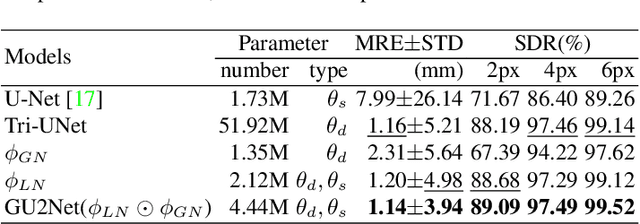
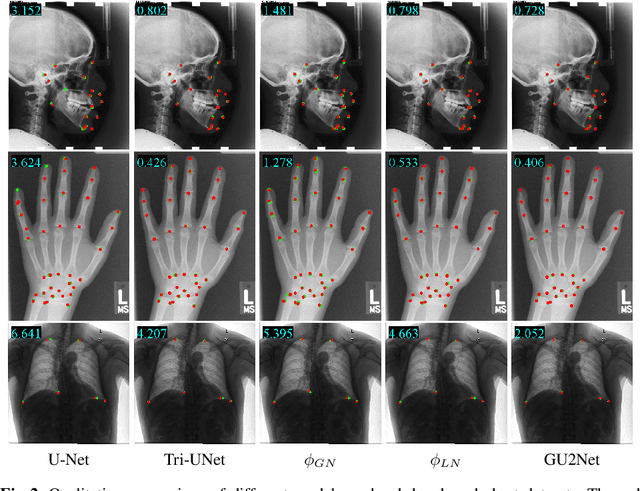
Detecting anatomical landmarks in medical images plays an essential role in understanding the anatomy and planning automated processing. In recent years, a variety of deep neural network methods have been developed to detect landmarks automatically. However, all of those methods are unary in the sense that a highly specialized network is trained for a single task say associated with a particular anatomical region. In this work, for the first time, we investigate the idea of "You Only Learn Once (YOLO)" and develop a universal anatomical landmark detection model to realize multiple landmark detection tasks with end-to-end training based on mixed datasets. The model consists of a local network and a global network: The local network is built upon the idea of universal UNet to learn multi-domain local features and the global network is a parallelly-duplicated sequential of dilated convolutions that extract global features to further disambiguate the landmark locations. It is worth mentioning that the new model design requires fewer parameters than models with standard convolutions to train. We evaluate our YOLO model on three X-ray datasets of 1,588 images on the head, hand, and chest, collectively contributing 62 landmarks. The experimental results show that our proposed universal model behaves largely better than any previous models trained on multiple datasets. It even beats the performance of the model that is trained separately for every single dataset.