 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWLV-RIT at HASOC-Dravidian-CodeMix-FIRE2020: Offensive Language Identification in Code-switched YouTube Comments
Paper and Code

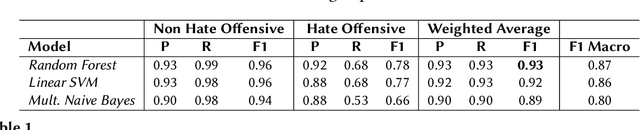
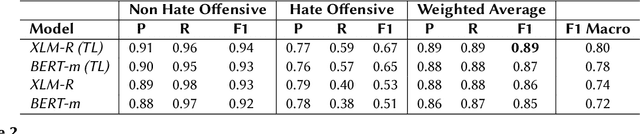

This paper describes the WLV-RIT entry to the Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) shared task 2020. The HASOC 2020 organizers provided participants with annotated datasets containing social media posts of code-mixed in Dravidian languages (Malayalam-English and Tamil-English). We participated in task 1: Offensive comment identification in Code-mixed Malayalam Youtube comments. In our methodology, we take advantage of available English data by applying cross-lingual contextual word embeddings and transfer learning to make predictions to Malayalam data. We further improve the results using various fine tuning strategies. Our system achieved 0.89 weighted average F1 score for the test set and it ranked 5th place out of 12 participants.