Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWide stochastic networks: Gaussian limit and PAC-Bayesian training
Paper and Code
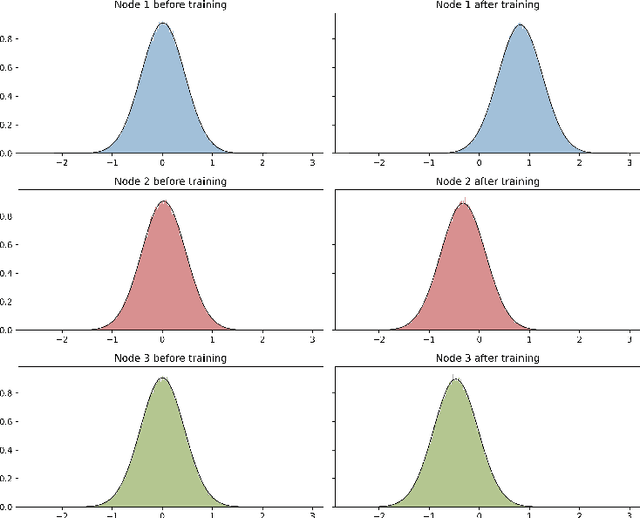
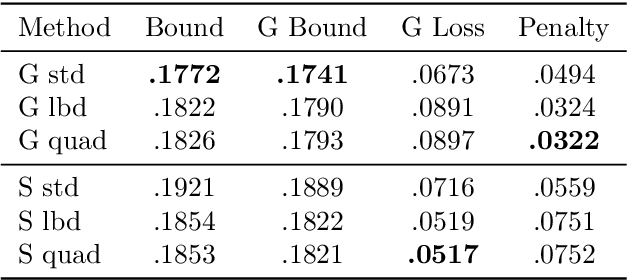
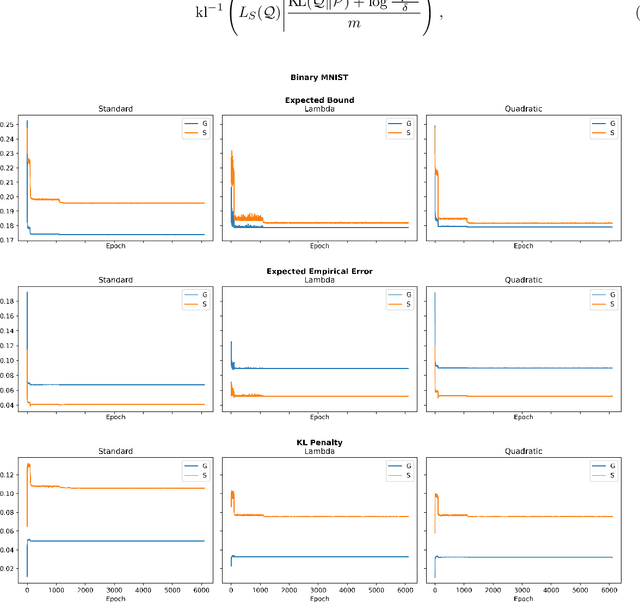
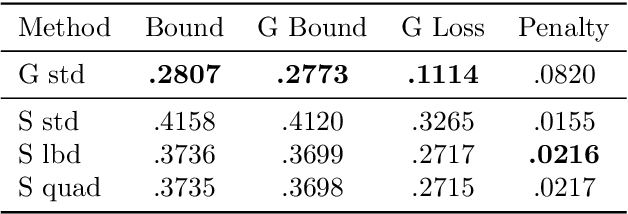
The limit of infinite width allows for substantial simplifications in the analytical study of overparameterized neural networks. With a suitable random initialization, an extremely large network is well approximated by a Gaussian process, both before and during training. In the present work, we establish a similar result for a simple stochastic architecture whose parameters are random variables. The explicit evaluation of the output distribution allows for a PAC-Bayesian training procedure that directly optimizes the generalization bound. For a large but finite-width network, we show empirically on MNIST that this training approach can outperform standard PAC-Bayesian methods.
* 20 pages, 2 figures
View paper on