 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWide Neural Networks Trained with Weight Decay Provably Exhibit Neural Collapse
Paper and Code
Oct 07, 2024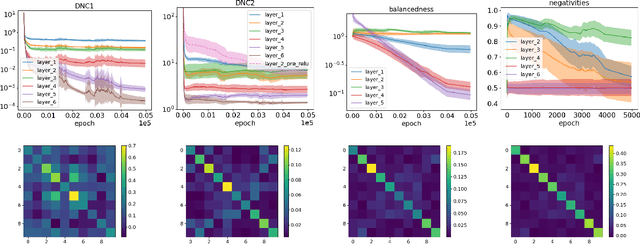


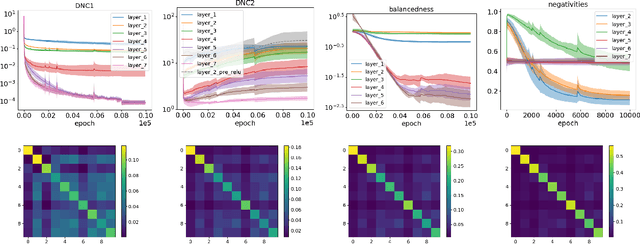
Deep neural networks (DNNs) at convergence consistently represent the training data in the last layer via a highly symmetric geometric structure referred to as neural collapse. This empirical evidence has spurred a line of theoretical research aimed at proving the emergence of neural collapse, mostly focusing on the unconstrained features model. Here, the features of the penultimate layer are free variables, which makes the model data-agnostic and, hence, puts into question its ability to capture DNN training. Our work addresses the issue, moving away from unconstrained features and studying DNNs that end with at least two linear layers. We first prove generic guarantees on neural collapse that assume (i) low training error and balancedness of the linear layers (for within-class variability collapse), and (ii) bounded conditioning of the features before the linear part (for orthogonality of class-means, as well as their alignment with weight matrices). We then show that such assumptions hold for gradient descent training with weight decay: (i) for networks with a wide first layer, we prove low training error and balancedness, and (ii) for solutions that are either nearly optimal or stable under large learning rates, we additionally prove the bounded conditioning. Taken together, our results are the first to show neural collapse in the end-to-end training of DNNs.